Quasi il seguito ideale di questa iniziativa di Michele Benvegnù, volevo segnalarvi che a partire da oggi i post relativi ai comandi Linux, e più in generale i post che troverete sotto la voce amministrazione di un sistema GNU/Linux, sono scaricabili in formato PDF; li trovate come sempre in alto nella barra di navigazione destra, sezione "Scarica in PDF".
Naturalmente si tratta dei post, i commenti per via della loro natura più dinamica resteranno a vostra disposizione sul blog. Un grazie a Michele per la sua rinnovata disponibilità, ed a voi tutti auguro una buona lettura. :-D
@:\>
lunedì 19 novembre 2007
sabato 17 novembre 2007
Linux: comandi info, apropos, whatis per ulteriori informazione sui comandi
Sempre per non perderci nella foresta dei comandi Linux, dopo il post scorso sull'uso di man, l'interfaccia da shell alla documentazione presente sul vostro sistema Linux, in questo post conclusivo sull'argomento vi mostro altri 3 comandi per accedere ad ulteriore documentazione:
Potrete saltare da una pagina all'altra premendo invio quando il cursore è su un termine che contiene un rimando ad un'altra pagina. Premendo u si torna al livello precedente, con n si passa alla pagina seguente, con p alla precedente, i torna all'indice, / permette di fare ricerche, ? mostra i comandi disponibili.
Passiamo ora al comando
Scopriamo così che ls si trova nella sezione 1 dei manuali e dalla descrizione del comando capiamo cosa fa, la stessa descrizione, ripeto, che il comando man ls presenta nella prima sezione NAME. In realtà
Tenetelo presente: quando chiedete a
Ultimo comando di cui ci occupiamo è
Bene, e con questo abbiamo terminato il veloce sguardo agli strumenti grazie alla quale avere rapidamente informazioni sui comandi Linux. Naturalmente rimane il web come ulteriore fonte d'informazione, ma lì non credo di dovervi dire qualcosa: voglio solo segnalarvi due ottime fonti di informazioni che trovate nella barra di navigazione sinistra, alla sezione "Risorse sul Web": si tratta di "Appunti di informatica libera" e di "Truelite"; entrambi in italiano, chiare, complete, e molto molto utili per approfondire quanto andremo a vedere nei prossimi post sull'argomento. A presto. :)
@:\>
info, whatis e apropos.Info in qualche modo è analogo a man: per usarlo basterà dare il comando info nomecomando e anch'esso permette di accedere alla documentazione dei comandi, ma le due documentazioni non sono equivalenti: alcune cose infatti che trovate nei file di man non le trovate in quelli di info e viceversa. Anche il sistema di consultazione è diverso: quello di info è un pò più ostico trattandosi di pagine ipertestuali.Potrete saltare da una pagina all'altra premendo invio quando il cursore è su un termine che contiene un rimando ad un'altra pagina. Premendo u si torna al livello precedente, con n si passa alla pagina seguente, con p alla precedente, i torna all'indice, / permette di fare ricerche, ? mostra i comandi disponibili.
Passiamo ora al comando
whatis. Nel post precedente vi avevo spiegato come i manuali sono raccolti in sezioni: whatis nomecomando restituisce il numero della sezione del manuale in cui ha trovato la stringa "nomecomando" ed una sua descrizione, quella che potete vedere nella sezione NAME quando ad esempio avete dato il comando man ls, proprio all'inizio della schermata. Esempio:$ whatis ls
ls (1) - list directory contentsScopriamo così che ls si trova nella sezione 1 dei manuali e dalla descrizione del comando capiamo cosa fa, la stessa descrizione, ripeto, che il comando man ls presenta nella prima sezione NAME. In realtà
whatis così non è poi di grandissima utilità, a meno di trovarci in questa situazione:$ whatis passwd
passwd (1) - change user password
passwd (1ssl) - compute password hashes
passwd (5) - the password fileWhatis ci restituisce tutte le occorrenze di passwd con tanto di indicazione della sezione in cui si trova e ovviamente la breve descrizione del comando. Per come è congegnato man, quando diamo il comando man passwd ci viene mostrata solo la prima occorrenza, per visualizzare le altre 2 occorre indicarle esplicitamente, per esempio:man 5 passwdTenetelo presente: quando chiedete a
man un certo comando ma vi compare altro, controllate con whatis la presenza di altre voci che siano maggiormente corrispondenti a quanto cercate.Ultimo comando di cui ci occupiamo è
apropos "nome comando": cerca la stringa corrispondente a "nome comando" nella sezione DESCRIPTION delle pagine visualizzate da man, notare l'uso degli apici per parole composte.Bene, e con questo abbiamo terminato il veloce sguardo agli strumenti grazie alla quale avere rapidamente informazioni sui comandi Linux. Naturalmente rimane il web come ulteriore fonte d'informazione, ma lì non credo di dovervi dire qualcosa: voglio solo segnalarvi due ottime fonti di informazioni che trovate nella barra di navigazione sinistra, alla sezione "Risorse sul Web": si tratta di "Appunti di informatica libera" e di "Truelite"; entrambi in italiano, chiare, complete, e molto molto utili per approfondire quanto andremo a vedere nei prossimi post sull'argomento. A presto. :)
@:\>
giovedì 15 novembre 2007
Linux: man, informazioni sui comandi
Abbiamo già visto nel post precedente, come la shell non sia altro che un'interfaccia di tipo testo con cui dare comandi a Linux. Non clicchiamo su qualcosa, niente tasto destro o sinistro: solo testo, puro testo, nient'altro che testo. Ed una vera foresta di comandi mnemonici da mandar giù, con ancora più opzioni da poter usare per ognuno di essi, in cui soprattutto chi proviene da Windows o più in generale gli amanti dell'interfaccia grafica potrebbe/protrebbero facilmente perdersi.
Prima di andare perciò dispersi in questa selva oscura, voglio condividere con voi altre informazioni di base per non perderci mai, o quanto meno ritrovarci nel caso "che la diritta via era smarrita". Linux infatti è molto ben documentato, e per ogni comando c'è la possibilità di averne immediatamente una descrizione e la lista della sue possibili opzione tramite un apposito comando: man.
Man è un'interfaccia ai manuali disponibili sul vostro sistema consultabili da shell. Prende in input i file contenenti questi manuali scritti in un linguaggio di formattazione chiamato Troff (come concetto analogo all'HTML nel senso che all'interno dello testo stesso vi sono anche le istruzioni di formattazione), e produce qualcosa di simile a quanto riportato più sotto.
Facciamo un esempio concreto: tramite il comando
(il $ rappresenta il prompt, anch'esso spiegato nel post precedente), otterrete quanto segue:
Come potete vedere man formatta a video una serie di informazioni sul comando ls:
- per comodità infatti il manuale è stato diviso in sezione, una per ogni tipologia di comandi, ls è nella prima (1), la sezione dei comandi utente (user commands);
- NAME contiene il nome del comando così come va scritto nella shell ed una sua breve descrizione;
- SINOPSYS indica come va usato il comando in tutti i possibili casi, comprese le eventuali opzioni e gli argomenti;
- DESCRIPTION fornisce una descrizione più dettagliata del comando;
- segue la lista dei possibili argomenti del comando con la loro descrizione.
Per muovervi all'interno di documenti molto lunghi premete i tasti "page up" e "page down" ("Pag con freccia all'insù" e "Pag con freccia all'ingiù" sulla vostra tastiera) e potrete andare su e giù nel testo visualizzandone la parte che v'interessa.
Cercate un termine all'interno del testo? Premete il tasto "/" (sopra il 7 nella tastiera italiana) e scrivete la stringa cercata, poi date invio. Man vi evidenzierà tutto le occorrenze trovate.
Ma non finisce qua: man fa altre mille cosette simpatiche. Quali? Beh, chi meglio di man stesso può dirvelo. Date il comando
Si esatto, come avrete già immaginato, abbiamo chiesto a man di visualizzare il suo stesso manuale. Consultatelo usando una Ubuntu, trovete in italiano tutta una serie di utili descrizioni sul modo in cui sono organizzati i manuali, e capirete meglio l'output di man quando avete chiesto informazioni sul comando ls.
Ultima cosa: quando avete terminato la consultazione e volete uscire dalla pagina di manuale, premete il tasto "q", sta per quit.
@:\>
Prima di andare perciò dispersi in questa selva oscura, voglio condividere con voi altre informazioni di base per non perderci mai, o quanto meno ritrovarci nel caso "che la diritta via era smarrita". Linux infatti è molto ben documentato, e per ogni comando c'è la possibilità di averne immediatamente una descrizione e la lista della sue possibili opzione tramite un apposito comando: man.
Man è un'interfaccia ai manuali disponibili sul vostro sistema consultabili da shell. Prende in input i file contenenti questi manuali scritti in un linguaggio di formattazione chiamato Troff (come concetto analogo all'HTML nel senso che all'interno dello testo stesso vi sono anche le istruzioni di formattazione), e produce qualcosa di simile a quanto riportato più sotto.
Facciamo un esempio concreto: tramite il comando
man ls visualizziamo le pagine del manuale del comando ls usato per avere la lista dei file contenuti in una directory. Aprite la shell (come fare lo trovate nel post precedente), e date il comando$ man ls(il $ rappresenta il prompt, anch'esso spiegato nel post precedente), otterrete quanto segue:
LS(1) User Commands LS(1)
NAME
ls - list directory contents
SYNOPSIS
ls [OPTION]... [FILE]...
DESCRIPTION
List information about the FILEs (the current directory by default). Sort entries alphabetically if none of -cftuvSUX nor --sort.
Mandatory arguments to long options are mandatory for short options too.
-a, --all
do not ignore entries starting with .
-A, --almost-all
do not list implied . and ..
--author
with -l, print the author of each file
-b, --escape
print octal escapes for nongraphic characters
--block-size=SIZE
use SIZE-byte blocks
-B, --ignore-backups
do not list implied entries ending with ~
-c with -lt: sort by, and show, ctime (time of last modification of file status information) with -l: show ctime and sort by name otherwise: sort
by ctime
-C list entries by columns
--color[=WHEN]
control whether color is used to distinguish file types. WHEN may be ‘never’, ‘always’, or ‘auto’
-d, --directory
list directory entries instead of contents, and do not dereference symbolic links
Manual page ls(1) line 1/208 18%Come potete vedere man formatta a video una serie di informazioni sul comando ls:
- per comodità infatti il manuale è stato diviso in sezione, una per ogni tipologia di comandi, ls è nella prima (1), la sezione dei comandi utente (user commands);
- NAME contiene il nome del comando così come va scritto nella shell ed una sua breve descrizione;
- SINOPSYS indica come va usato il comando in tutti i possibili casi, comprese le eventuali opzioni e gli argomenti;
- DESCRIPTION fornisce una descrizione più dettagliata del comando;
- segue la lista dei possibili argomenti del comando con la loro descrizione.
Per muovervi all'interno di documenti molto lunghi premete i tasti "page up" e "page down" ("Pag con freccia all'insù" e "Pag con freccia all'ingiù" sulla vostra tastiera) e potrete andare su e giù nel testo visualizzandone la parte che v'interessa.
Cercate un termine all'interno del testo? Premete il tasto "/" (sopra il 7 nella tastiera italiana) e scrivete la stringa cercata, poi date invio. Man vi evidenzierà tutto le occorrenze trovate.
Ma non finisce qua: man fa altre mille cosette simpatiche. Quali? Beh, chi meglio di man stesso può dirvelo. Date il comando
$ man manSi esatto, come avrete già immaginato, abbiamo chiesto a man di visualizzare il suo stesso manuale. Consultatelo usando una Ubuntu, trovete in italiano tutta una serie di utili descrizioni sul modo in cui sono organizzati i manuali, e capirete meglio l'output di man quando avete chiesto informazioni sul comando ls.
Ultima cosa: quando avete terminato la consultazione e volete uscire dalla pagina di manuale, premete il tasto "q", sta per quit.
@:\>
mercoledì 14 novembre 2007
Linux: la shell, la vostra centrale di comando
Con il post "Linux: avvio e funzionamento del kernel" abbiamo concluso una prima serie di post intesi a comprendere le basi dell'architettura di un sistema Linux. I prossimi sono post di passaggio prima di addentrarci nella giungla dei comandi Linux: una vera foresta in cui sopratutto chi proviene da Windows o più in generale gli amanti dell'interfaccia grafica, potrebbero facilmente perdersi. E in questo non siamo per niente aiutati dal front-end, dall'interfaccia usata per dare i comandi: la shell.
La shell non è altro che un'interfaccia di tipo testo fra noi e Linux. Come tutto il resto anch'essa è un programma, ed infatti esiste più di una shell. Alcune sono caratterizzate da grande leggerezza e un fabbisogno limitato di risorse, altre da comandi molto potenti, altre ancora dall'aderenza agli standard Posix. Quella di default sulla maggioranza delle distribuzione, tra cui anche le nostre due di riferimento, Mandriva e Ubuntu, è la bash (Bourne Again SHell).
Il nome ed il modo di avviare la bash cambia a seconda che stiate usando l'interfaccia grafica Gnome (quella di Ubuntu per esempio) o KDE (di default in Mandriva): nella prima si chiama Terminale e potete avviarla come in fig. 1,
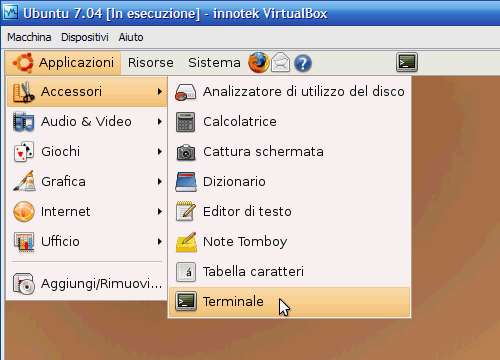
fig. 1
nella seconda si chiama Konsole (è consuetudine aggiugere una k iniziale nelle applicazioni KDE) e la potete avviare come in fig. 2.
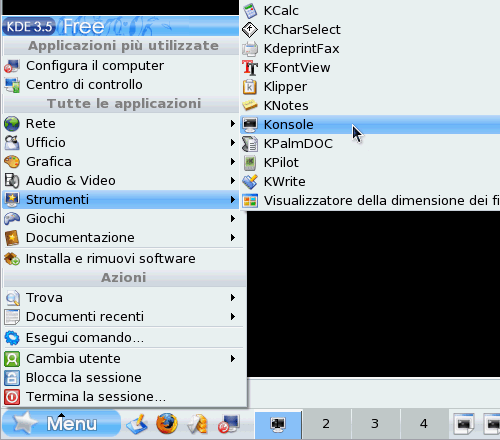
fig. 2
Una volta avviata, la shell mostrerà un prompt, un testo all'inizio di ogni riga, che contiene una serie di informazioni utili; vediamo quelle della bash in Ubuntu (fig. 3):
- la parte prima della "@" è il vostro nome utente (o userid);
- la parte successiva alla "@" che termina dove ci sono i ":" è il nome con cui viene vista la vostra macchina all'interno di una rete;
- il simbolo "~" (tilde) per convenzione in Linux indica la vostra directory home. Dato che la home di un utente ha come nome quello dell'utente stesso, in fig. 3 allora ci troviamo nella directory
- il simbolo "$" (dollaro) finale sta ad indicare che in questo momento siete un utente normale, se fosse il simbolo "#" invece siete l'amministratore; ricordatelo quando siete in dubbio se siete in modalità amministrativa o utente normale, nel primo caso dovete essere molto più attenti per la portata maggiore dei danni che potreste fare.

fig. 3
Due sono le funzionalità della bash che voglio mostrarvi, sono semplici ma di grande utilità; riguardano entrambi lo storico dei comandi precedentemente dati:
1) premendo il tasto "freccia su" della vostra tastiera potrete navigare all'indietro ed uno alla volta, tutto lo storico dei comandi già dati nella shell. Fate una prova, date i comandi:
Vi ricordo che il simbolo dollaro "$" del prompt sta ad indicare che siete in modalità utente normale. Ora premete "freccia su" e uno alla volta lì vedrete ricomparire tutti in ordine inverso, dal comando più recente a quello più datato.
2) dando il comando
Ecco, con solo questi due piccoli aiuti da parte della shell, il vostro lavoro diventerà molto più veloce e leggero, niente più riscrittura degli stessi noiosi comandi, soprattutto quando sono composti dal concatenamento di tanti singoli comandi che prossimamente vedremo.
@:\>
La shell non è altro che un'interfaccia di tipo testo fra noi e Linux. Come tutto il resto anch'essa è un programma, ed infatti esiste più di una shell. Alcune sono caratterizzate da grande leggerezza e un fabbisogno limitato di risorse, altre da comandi molto potenti, altre ancora dall'aderenza agli standard Posix. Quella di default sulla maggioranza delle distribuzione, tra cui anche le nostre due di riferimento, Mandriva e Ubuntu, è la bash (Bourne Again SHell).
Il nome ed il modo di avviare la bash cambia a seconda che stiate usando l'interfaccia grafica Gnome (quella di Ubuntu per esempio) o KDE (di default in Mandriva): nella prima si chiama Terminale e potete avviarla come in fig. 1,
fig. 1
nella seconda si chiama Konsole (è consuetudine aggiugere una k iniziale nelle applicazioni KDE) e la potete avviare come in fig. 2.
fig. 2
Una volta avviata, la shell mostrerà un prompt, un testo all'inizio di ogni riga, che contiene una serie di informazioni utili; vediamo quelle della bash in Ubuntu (fig. 3):
- la parte prima della "@" è il vostro nome utente (o userid);
- la parte successiva alla "@" che termina dove ci sono i ":" è il nome con cui viene vista la vostra macchina all'interno di una rete;
- il simbolo "~" (tilde) per convenzione in Linux indica la vostra directory home. Dato che la home di un utente ha come nome quello dell'utente stesso, in fig. 3 allora ci troviamo nella directory
/home/occhipervinca;- il simbolo "$" (dollaro) finale sta ad indicare che in questo momento siete un utente normale, se fosse il simbolo "#" invece siete l'amministratore; ricordatelo quando siete in dubbio se siete in modalità amministrativa o utente normale, nel primo caso dovete essere molto più attenti per la portata maggiore dei danni che potreste fare.
fig. 3
Due sono le funzionalità della bash che voglio mostrarvi, sono semplici ma di grande utilità; riguardano entrambi lo storico dei comandi precedentemente dati:
1) premendo il tasto "freccia su" della vostra tastiera potrete navigare all'indietro ed uno alla volta, tutto lo storico dei comandi già dati nella shell. Fate una prova, date i comandi:
$ ls che vi presenta la lista dei file della directory in cui vi trovate,$ cd / per portarvi nella radice del vostro filesystem (è pressappoco come essere in C: in Windows),$ ls -l, che mostra molte più informazioni del solo ls.Vi ricordo che il simbolo dollaro "$" del prompt sta ad indicare che siete in modalità utente normale. Ora premete "freccia su" e uno alla volta lì vedrete ricomparire tutti in ordine inverso, dal comando più recente a quello più datato.
2) dando il comando
hystory vedrete riportata tutta la lista dei comandi dati preceduti da un numero. Se volete eseguire un certo comando presente nella lista, è sufficiente dare !numero per vederlo eseguito.Ecco, con solo questi due piccoli aiuti da parte della shell, il vostro lavoro diventerà molto più veloce e leggero, niente più riscrittura degli stessi noiosi comandi, soprattutto quando sono composti dal concatenamento di tanti singoli comandi che prossimamente vedremo.
@:\>
martedì 13 novembre 2007
Linux: avvio e funzionamento del kernel
All'accensione del PC, il primo programma ad essere eseguito è contenuto direttamente nel firmware della macchina: il BIOS (Basic Input/Output System). Questo programma effettua tutta una serie di controlli sull'hardware che se conclusi correttamente portano alla fase successiva: l'avvio, dal dispositivo indicato nelle impostazioni del bios, del bootloader. L'unico compito del bootloader è cercare un'immagine del kernel, caricarla in memoria e avviarla.
Partito il kernel, questi prende il controllo della macchina, effettua una serie di operazione di inizializzazione come la scansione delle periferiche disponibili, e infine lancia il primo processo di un sistema Linux, init. In realtà questa è solo una convenzione sul nome del primo processo da lanciare; in sistemi embedded ad esempio, cioè quei sistemi adibiti ad un singolo compito quali un comune telefonino, in genere viene lanciato altro.
Init, sfruttando la possibilità di un processo di lanciare a sua volta un altro processo (il primo è detto padre, il secondo figlio, Init è quindi il padre di tutti i processi Linux), lancia altri programmi che a loro volta lanciano ancora altri programmi, tutto questo fino a che sono partiti tutti i programmi che servono per il corretto funzionamento dell'intero sistema operativo.
Ma come funziona l'intero sistema operativo basandosi su un kernel che può fare solo le poche cose già viste nel post "Linux: architettura di base"? Guardate fig. 1 mentre vi spiego.
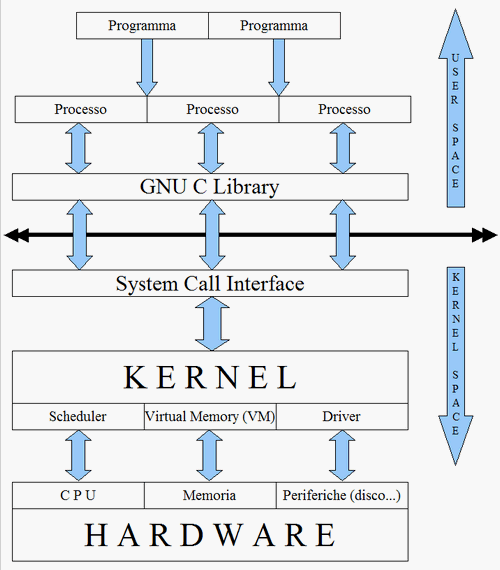
fig. 1
Abbiamo già accennato al fatto che il kernel è l'unico che può accedere direttamente all'hardware della macchina: grazie alle sue tre sezioni, scheduler, virtual memory, driver sfrutta la potenza e le risorse della macchina e le rende disponibili ai processi.
Quando un programma (e quindi uno dei processi da cui è costituito) ha bisogno per esempio di altra memoria, la chiede ad un apposito programma contenuto nel sottostante livello chiamato GNU C Library (guardate fig. 1), una serie di programmi scritti in linguaggio C. Questo a sua volta, invoca un'apposita funzione del sottostante livello chiamato System Call Interface (Interfaccia alle Chiamate di Sistema). Queste sono funzioni rese disponibili dal kernel per poterlo informare che si ha bisogno di qualcosa da lui. Ora il kernel sa che un processo ha bisogno di più memoria, e tramite l'apposita sezione del Virtual Memory provvede a fornirgliela.
Si può notare una netta separazione fra lo spazio in cui si trovano a girare i programmi, detto User Space (Spazio Utente), da cui non vi accesso diretto all'hardware, e lo spazio in cui gira il kernel, detto Kernel Space, da cui invece si accede direttamente all'hardware; ecco perché solo il kernel può accedere direttamente all'hardare, mentre i processi girando in user space ne sono impossibilitati.
Il compito del kernel è unicamente quello di rendere disponibili le risorse hardware ai processi facendo da interfaccia fra questi due, di suo non effettua nessun'altra operazione. E' questo il motivo per cui in Linux tutto è realizzato tramite un programma: dalla semplice copia di un file all'intero filesystem passando per l'interfaccia grafica, si tratta sempre di programmi eseguiti in User Space, il kernel in se non ha disponibile nessuna di queste funzionalità.
Lungi dell'essere un limite, questo è invece un grande vantaggio di Linux: è per questo motivo che ad esempio, potete usare più interfacce grafiche (due su tutte, Gnome e KDE) invece dell'unica che ad esempio si può utilizzare in Windows. Ed è sempre per questo motivo che, se in Windows potete usare il solo filesystem NTFS (oppure il FAT, ormai obsoleto ma ancora utile in certe situazione), in Linux ne potete usare una buona decina tra cui anche NTFS.
Chi ha avuto modo di installare Ubuntu 7.10 direttamente sul PC, senza usare VirtualBox o altri virtualizzatori, si sarà accorto come la partizione di Windows gli compare direttamente sul desktop come fosse un normale disco rigido di Linux: potete navigarlo a vostro piacimento e fare qualunque operazione vogliate sui file che contiene nonostante si tratti di un filesystem Windows. Ecco, questa è la potenza dell'approccio "tutto è un programma" di Linux.
@:\>
Partito il kernel, questi prende il controllo della macchina, effettua una serie di operazione di inizializzazione come la scansione delle periferiche disponibili, e infine lancia il primo processo di un sistema Linux, init. In realtà questa è solo una convenzione sul nome del primo processo da lanciare; in sistemi embedded ad esempio, cioè quei sistemi adibiti ad un singolo compito quali un comune telefonino, in genere viene lanciato altro.
Init, sfruttando la possibilità di un processo di lanciare a sua volta un altro processo (il primo è detto padre, il secondo figlio, Init è quindi il padre di tutti i processi Linux), lancia altri programmi che a loro volta lanciano ancora altri programmi, tutto questo fino a che sono partiti tutti i programmi che servono per il corretto funzionamento dell'intero sistema operativo.
Ma come funziona l'intero sistema operativo basandosi su un kernel che può fare solo le poche cose già viste nel post "Linux: architettura di base"? Guardate fig. 1 mentre vi spiego.
fig. 1
Abbiamo già accennato al fatto che il kernel è l'unico che può accedere direttamente all'hardware della macchina: grazie alle sue tre sezioni, scheduler, virtual memory, driver sfrutta la potenza e le risorse della macchina e le rende disponibili ai processi.
Quando un programma (e quindi uno dei processi da cui è costituito) ha bisogno per esempio di altra memoria, la chiede ad un apposito programma contenuto nel sottostante livello chiamato GNU C Library (guardate fig. 1), una serie di programmi scritti in linguaggio C. Questo a sua volta, invoca un'apposita funzione del sottostante livello chiamato System Call Interface (Interfaccia alle Chiamate di Sistema). Queste sono funzioni rese disponibili dal kernel per poterlo informare che si ha bisogno di qualcosa da lui. Ora il kernel sa che un processo ha bisogno di più memoria, e tramite l'apposita sezione del Virtual Memory provvede a fornirgliela.
Si può notare una netta separazione fra lo spazio in cui si trovano a girare i programmi, detto User Space (Spazio Utente), da cui non vi accesso diretto all'hardware, e lo spazio in cui gira il kernel, detto Kernel Space, da cui invece si accede direttamente all'hardware; ecco perché solo il kernel può accedere direttamente all'hardare, mentre i processi girando in user space ne sono impossibilitati.
Il compito del kernel è unicamente quello di rendere disponibili le risorse hardware ai processi facendo da interfaccia fra questi due, di suo non effettua nessun'altra operazione. E' questo il motivo per cui in Linux tutto è realizzato tramite un programma: dalla semplice copia di un file all'intero filesystem passando per l'interfaccia grafica, si tratta sempre di programmi eseguiti in User Space, il kernel in se non ha disponibile nessuna di queste funzionalità.
Lungi dell'essere un limite, questo è invece un grande vantaggio di Linux: è per questo motivo che ad esempio, potete usare più interfacce grafiche (due su tutte, Gnome e KDE) invece dell'unica che ad esempio si può utilizzare in Windows. Ed è sempre per questo motivo che, se in Windows potete usare il solo filesystem NTFS (oppure il FAT, ormai obsoleto ma ancora utile in certe situazione), in Linux ne potete usare una buona decina tra cui anche NTFS.
Chi ha avuto modo di installare Ubuntu 7.10 direttamente sul PC, senza usare VirtualBox o altri virtualizzatori, si sarà accorto come la partizione di Windows gli compare direttamente sul desktop come fosse un normale disco rigido di Linux: potete navigarlo a vostro piacimento e fare qualunque operazione vogliate sui file che contiene nonostante si tratti di un filesystem Windows. Ecco, questa è la potenza dell'approccio "tutto è un programma" di Linux.
@:\>
lunedì 12 novembre 2007
Linux: architettura di base
Che lo abbiate installato su una macchina virtuale di VirtualBox oppure direttamente sul vostro PC, da un liveCD oppure da Windows usando Wubi, è arrivato il momento di guardare da vicino come funziona un sistema operativo Linux.
Linux è un sistema operativo multitasking e multiutente, ossia può gestire più processi e più utenti contemporaneamente (un processo è l'unita minima di elaborazione di un programma).
Il cuore di un sistema operativo è il kernel. Quello di Linux si occupa solamente di una cosa: eseguire processi sfruttando le risorse hardware della macchina su cui gira. Tutto il resto, dai servizi di sistema all'interfaccia grafica, è ottenuto facendo girare un programma. Il kernel di per se non offre nessuno di questi servizi: non offre ad esempio funzionalità per copiare i file, non offre un'interfaccia utente, ne di testo ne di tipo grafico.
Quando usate un'interfaccia grafica come Gnome o KDE, queste non sono funzionalità offerte dal kernel, bensì normalissimi programmi esterni al kernel, al pari di un OpenOffice.org o Firefox. Ecco perché in Linux potete scegliere più interfacce grafiche, è semplicemente un programma come tutti gli altri. In Windows invece l'interfaccia grafica è integrata nel sistema operativo, ed in alcune versioni, anche il browser per la navigazione Internet.
Quando diciamo Linux poi, non stiamo riferendoci all'intero sistema operativo, ma solo al kernel. Sfruttando i servizi che questi mette a disposizione, una moltitudine di programmi si occupa di fornire tutte le funzionalità che ci si aspetta da un moderno sistema operativo. Questi programmi arrivano direttamente, o derivano in qualche modo, dal progetto GNU della Free Software Foundation: ecco perché in generale si parla di sistema operativo GNU/Linux.
Infine, quella che comunemente viene chiamata distribuzione, Debian, Ubuntu, openSUSE, RedHat solo per fare qualche nome fra le più conosciute, è l'insieme del sistema operativo GNU/Linux più una raccolta coerente di programmi usati dagli utenti per le loro normali attività: programmi di grafica, produttività personale, navigazione Internet, player audio/video e così via.
Da qui in poi però, per semplificarci la vita, un sistema operativo GNU/Linux continueremo a chiamarlo con il solo termine Linux.
Ok, accordatici sulla terminologia da usare, torniamo ora ad occuparci del kernel vedendo quali sono le poche ma fondamentali mansioni che svolge per darci l'unico servizio che offre: eseguire processi, l'unità minima di elaborazione di un programma. Queste mansioni sono svolte dalle tre sottosezioni del KERNEL visibili in fig. 1:
fig. 1
- gestione dei processi tramite lo Scheduler.
Questa parte del kernel si occupa di tutto ciò che riguarda la gestione di un processo, ad esempio di stabilire l'ordine di esecuzione dei processi, l'esecuzione stessa, la sospensione dell'elaborazione, la ripresa, lo stop e così via.
- gestione della memoria tramite il Virtual Memory (VM).
La memoria fisica non è liberamente accessibile ai processi. E' il VM che, anche con l'aiuto del Memory Management Unit (MMU), apposita unità presente direttamente nell'hardware dei microprocessori, rimappa opportunamente quella fisica in uno spazio virtuale che rende disponibile al processo. In questo modo, ogni processo non accede mai alla memoria reale del sistema, ma solo a quella resagli disponibile dal VM.
Sigillato all'interno del suo spazio di memoria, il processo non può creare problemi accedendo per sbaglio allo spazio di un altro processo (chi ha usato le prime versioni di Windows, sa quanto fossero frequenti i blocchi dell'intero sistema causati proprio da problemi di questo tipo). Quando la memoria RAM poi per qualche motivo diventa insufficiente, è sempre il VM a gestire lo swap, lo spostamento cioè di parti della memoria sul disco fisso per liberare spazio.
- gestione delle periferiche tramite i Driver.
Questa indicazione generica è relativa a quella parte del kernel che si occupa di accedere alle periferiche rendendole disponibili ai programmi. La particolarità di questa sezione è che fornisce un modalità comune (un'interfaccia) di accesso a periferiche anche molto diverse fra loro, porte seriali, dischi rigidi, scheda audio tanto per fare degli esempi, trattandole tutte come se fossero dei file; da qui uno dei motti di Linux: tutto è un file. Vedremo successivamente come ciò sia possibile e i vantaggi di questo approccio.
Ecco, questa è in estrema sintesi l'architettura di un sistema Linux, giusto per iniziare a capire; in realtà le cose sono ben più complesse, provate a dare un'occhiata a questa mappa interattiva del kernel di Linux e vi renderete conto.
@:\>
Linux è un sistema operativo multitasking e multiutente, ossia può gestire più processi e più utenti contemporaneamente (un processo è l'unita minima di elaborazione di un programma).
Il cuore di un sistema operativo è il kernel. Quello di Linux si occupa solamente di una cosa: eseguire processi sfruttando le risorse hardware della macchina su cui gira. Tutto il resto, dai servizi di sistema all'interfaccia grafica, è ottenuto facendo girare un programma. Il kernel di per se non offre nessuno di questi servizi: non offre ad esempio funzionalità per copiare i file, non offre un'interfaccia utente, ne di testo ne di tipo grafico.
Quando usate un'interfaccia grafica come Gnome o KDE, queste non sono funzionalità offerte dal kernel, bensì normalissimi programmi esterni al kernel, al pari di un OpenOffice.org o Firefox. Ecco perché in Linux potete scegliere più interfacce grafiche, è semplicemente un programma come tutti gli altri. In Windows invece l'interfaccia grafica è integrata nel sistema operativo, ed in alcune versioni, anche il browser per la navigazione Internet.
Quando diciamo Linux poi, non stiamo riferendoci all'intero sistema operativo, ma solo al kernel. Sfruttando i servizi che questi mette a disposizione, una moltitudine di programmi si occupa di fornire tutte le funzionalità che ci si aspetta da un moderno sistema operativo. Questi programmi arrivano direttamente, o derivano in qualche modo, dal progetto GNU della Free Software Foundation: ecco perché in generale si parla di sistema operativo GNU/Linux.
Infine, quella che comunemente viene chiamata distribuzione, Debian, Ubuntu, openSUSE, RedHat solo per fare qualche nome fra le più conosciute, è l'insieme del sistema operativo GNU/Linux più una raccolta coerente di programmi usati dagli utenti per le loro normali attività: programmi di grafica, produttività personale, navigazione Internet, player audio/video e così via.
Da qui in poi però, per semplificarci la vita, un sistema operativo GNU/Linux continueremo a chiamarlo con il solo termine Linux.
Ok, accordatici sulla terminologia da usare, torniamo ora ad occuparci del kernel vedendo quali sono le poche ma fondamentali mansioni che svolge per darci l'unico servizio che offre: eseguire processi, l'unità minima di elaborazione di un programma. Queste mansioni sono svolte dalle tre sottosezioni del KERNEL visibili in fig. 1:
fig. 1
- gestione dei processi tramite lo Scheduler.
Questa parte del kernel si occupa di tutto ciò che riguarda la gestione di un processo, ad esempio di stabilire l'ordine di esecuzione dei processi, l'esecuzione stessa, la sospensione dell'elaborazione, la ripresa, lo stop e così via.
- gestione della memoria tramite il Virtual Memory (VM).
La memoria fisica non è liberamente accessibile ai processi. E' il VM che, anche con l'aiuto del Memory Management Unit (MMU), apposita unità presente direttamente nell'hardware dei microprocessori, rimappa opportunamente quella fisica in uno spazio virtuale che rende disponibile al processo. In questo modo, ogni processo non accede mai alla memoria reale del sistema, ma solo a quella resagli disponibile dal VM.
Sigillato all'interno del suo spazio di memoria, il processo non può creare problemi accedendo per sbaglio allo spazio di un altro processo (chi ha usato le prime versioni di Windows, sa quanto fossero frequenti i blocchi dell'intero sistema causati proprio da problemi di questo tipo). Quando la memoria RAM poi per qualche motivo diventa insufficiente, è sempre il VM a gestire lo swap, lo spostamento cioè di parti della memoria sul disco fisso per liberare spazio.
- gestione delle periferiche tramite i Driver.
Questa indicazione generica è relativa a quella parte del kernel che si occupa di accedere alle periferiche rendendole disponibili ai programmi. La particolarità di questa sezione è che fornisce un modalità comune (un'interfaccia) di accesso a periferiche anche molto diverse fra loro, porte seriali, dischi rigidi, scheda audio tanto per fare degli esempi, trattandole tutte come se fossero dei file; da qui uno dei motti di Linux: tutto è un file. Vedremo successivamente come ciò sia possibile e i vantaggi di questo approccio.
Ecco, questa è in estrema sintesi l'architettura di un sistema Linux, giusto per iniziare a capire; in realtà le cose sono ben più complesse, provate a dare un'occhiata a questa mappa interattiva del kernel di Linux e vi renderete conto.
@:\>
Amministrazione di sistemi Linux: premessa
Una doverosa premessa. Scordatevi sin d'ora la vostra interfaccia grafica preferita per dare i comandi: non cliccheremo sul file per cancellarlo, è una cosa intuitiva che chiunque venga da Windows riuscirà a fare benissimo anche su Linux, daremo invece il relativo comando rm (remove) da shell (l'interfaccia testuale di Linux, tipo finestra del DOS su Windows ma enormemente più potente). Per quanto possa sembrare astruso usare un'interfaccia testuale invece di una comodissima Gnome o KDE, tutto ciò ha perfettamente senso. Vediamone i motivi principali:
- non sempre è disponibile un'interfaccia grafica: soprattutto se il sistema è in panne, ma anche perché state lavorando su una macchina vecchia che non c'è la fa a far girare un'interfaccia grafica, oppure perché siete su un server e preferite risparmiare le pesanti risorse che un'interfaccia grafica consuma, potreste trovarvi ad avere a disposizione solo la riga di comando, sempre presente in ogni sistema.
- le interfacce grafiche hanno bisogno continuo di interazione: occorre stare lì continuamente a cliccare su qualcosa per scegliere opzioni e dare comandi. Immaginate di dover rinominare un migliaio di file: dovete cliccare sul file, scegliere in qualche modo l'opzione di rinomina del file, scrivere il nome del file, renderlo effettivo; ricominciare d'accapo tutto ciò e ripeterlo per tutti i mille file. Beh, potete spendere meglio il vostro tempo: lanciate uno script (una sequenza di comandi registrati su un file, come i file .bat di Windows per capirci) e nel frattempo vi bevete un buon caffè (se la vostra macchina è lenta nello svolgere l'operazione).
- le interfacce grafiche non rendono sempre disponibili all'utente tutti i comandi realmente presenti: molto spesso i comandi e le opzioni che l'interfaccia grafica rende disponibili sono solo una parte di tutti quelli disponibili, per poter usare gli altri bisogna scriverli dalla riga di comando.
- l'uso della riga di comando è più elastico di quello dell'interfaccia grafica: tramite una sequenza di opportuni comandi (i già citati script), è possibile creare nuove operazioni completamente automatizzate. In realtà ciò sarebbe possibile anche dall'interfaccia grafica usando uno degli appositi programmi che registrano la nostra attività sullo schermo (pulsanti cliccati, opzioni scelte), per poi ripeterla come un unico comando. Dato che gli script sono alla fine una vera e propria forma di programmazione, possiamo però prevedere, a seconda della situazione, l'esecuzione di alcuni comandi o di altri, rendendo il tutto molto più adattabile alle situazioni che si presentano “in corso d'opera” cioè durante l'esecuzione stessa dello script.
- l'interfaccia grafica nasconde molte delle cose che succedono nel dietro le quinte: nella metafora del teatro, se voi siete lo spettatore, cioè l'utente normale che vuole: avviare Linux, scrivere il suo documento con OpenOffice.org, spedirlo come allegato via e-mail, allora l'interfaccia grafica va benissimo. Ma se siete l'attore, cioè l'amministratore del sistema, allora avete bisogno di sapere anche cosa accade davvero nel dietro le quinte e sapervi muovere in esso. Poi, quando avrete imparato, saprete muovervi sia sul palco che dietro il palco, e saprete quando è il momento di essere davanti e quando dietro il palco stesso.
Fuor di metafora: quando saprete bene cosa accade sul vostro sistema, saprete anche come non complicarsi la vita usando di volta in volta, l'interfaccia grafica o quella a riga di comando a seconda delle esigenze, ma sapendo bene, nell'uno e nell'altro caso, cosa avviene davvero e come mantenere il controllo totale del sistema a voi affidato.
Il materiale sarà valido per Linux in tutte le sue incarnazione; pertanto, se avete voglia di capire davvero cosa c'è sotto il cofano della vostra distribuzione preferita, non vi resta che seguire i prossimi post sull'argomento.
@:\>
- non sempre è disponibile un'interfaccia grafica: soprattutto se il sistema è in panne, ma anche perché state lavorando su una macchina vecchia che non c'è la fa a far girare un'interfaccia grafica, oppure perché siete su un server e preferite risparmiare le pesanti risorse che un'interfaccia grafica consuma, potreste trovarvi ad avere a disposizione solo la riga di comando, sempre presente in ogni sistema.
- le interfacce grafiche hanno bisogno continuo di interazione: occorre stare lì continuamente a cliccare su qualcosa per scegliere opzioni e dare comandi. Immaginate di dover rinominare un migliaio di file: dovete cliccare sul file, scegliere in qualche modo l'opzione di rinomina del file, scrivere il nome del file, renderlo effettivo; ricominciare d'accapo tutto ciò e ripeterlo per tutti i mille file. Beh, potete spendere meglio il vostro tempo: lanciate uno script (una sequenza di comandi registrati su un file, come i file .bat di Windows per capirci) e nel frattempo vi bevete un buon caffè (se la vostra macchina è lenta nello svolgere l'operazione).
- le interfacce grafiche non rendono sempre disponibili all'utente tutti i comandi realmente presenti: molto spesso i comandi e le opzioni che l'interfaccia grafica rende disponibili sono solo una parte di tutti quelli disponibili, per poter usare gli altri bisogna scriverli dalla riga di comando.
- l'uso della riga di comando è più elastico di quello dell'interfaccia grafica: tramite una sequenza di opportuni comandi (i già citati script), è possibile creare nuove operazioni completamente automatizzate. In realtà ciò sarebbe possibile anche dall'interfaccia grafica usando uno degli appositi programmi che registrano la nostra attività sullo schermo (pulsanti cliccati, opzioni scelte), per poi ripeterla come un unico comando. Dato che gli script sono alla fine una vera e propria forma di programmazione, possiamo però prevedere, a seconda della situazione, l'esecuzione di alcuni comandi o di altri, rendendo il tutto molto più adattabile alle situazioni che si presentano “in corso d'opera” cioè durante l'esecuzione stessa dello script.
- l'interfaccia grafica nasconde molte delle cose che succedono nel dietro le quinte: nella metafora del teatro, se voi siete lo spettatore, cioè l'utente normale che vuole: avviare Linux, scrivere il suo documento con OpenOffice.org, spedirlo come allegato via e-mail, allora l'interfaccia grafica va benissimo. Ma se siete l'attore, cioè l'amministratore del sistema, allora avete bisogno di sapere anche cosa accade davvero nel dietro le quinte e sapervi muovere in esso. Poi, quando avrete imparato, saprete muovervi sia sul palco che dietro il palco, e saprete quando è il momento di essere davanti e quando dietro il palco stesso.
Fuor di metafora: quando saprete bene cosa accade sul vostro sistema, saprete anche come non complicarsi la vita usando di volta in volta, l'interfaccia grafica o quella a riga di comando a seconda delle esigenze, ma sapendo bene, nell'uno e nell'altro caso, cosa avviene davvero e come mantenere il controllo totale del sistema a voi affidato.
Il materiale sarà valido per Linux in tutte le sue incarnazione; pertanto, se avete voglia di capire davvero cosa c'è sotto il cofano della vostra distribuzione preferita, non vi resta che seguire i prossimi post sull'argomento.
@:\>
Linux: iniziamo
Nello scorso post, "Linux: che dite, approfondiamo?", vi avevo parlato delle motivazioni che mi hanno portato alla decisione di darci dentro con Linux. Niente più atti di fede, niente più ricette precotte, è arrivato il momento di guardare Linux in modo più organico, più organizzato, cominciando a dare un senso a cose che sembrano spuntare dal nulla, a comandi che sembrano parole dall'effetto magico.
In realtà avevo giù scritto un paio di post in proposito. Non so se li abbiate letti, ma sono la base da cui partiremo per costruire un percorso di apprendimento. Ho deciso perciò di spostarli ad oggi, così che possiate leggerli, o semplicemente farne un breve ripasso. La curva di apprendimento di Linux non è proprio tra le più agevoli, anzi, a dirla tutta, è abbastanza ripida. Ci metterò tutto l'impegno a semplificarvi il più possibile la cosa, aiutatemi mettendoci tutta la pazienza necessaria.
E statene certi, ne varrà la pena. :-)
@:\>
In realtà avevo giù scritto un paio di post in proposito. Non so se li abbiate letti, ma sono la base da cui partiremo per costruire un percorso di apprendimento. Ho deciso perciò di spostarli ad oggi, così che possiate leggerli, o semplicemente farne un breve ripasso. La curva di apprendimento di Linux non è proprio tra le più agevoli, anzi, a dirla tutta, è abbastanza ripida. Ci metterò tutto l'impegno a semplificarvi il più possibile la cosa, aiutatemi mettendoci tutta la pazienza necessaria.
E statene certi, ne varrà la pena. :-)
@:\>
sabato 10 novembre 2007
Linux: che dite, approfondiamo?
Della serie: riflessioni sotto la doccia... avrete notato che in questi giorni non ho messo online nuovi post. Mi sono preso un attimo di pausa per staccare un pò da tutto, blog compreso, e lasciare lo spazio perché qualcosa di nuovo emergesse.
In fondo questo blog, a dispetto dei suoi stessi post che sono in gran parte dedicati alla virtualizzazione ed a VirtualBox in particolare, non ha un argomento prefissato, se non quanto compreso nel sottotitolo del blog stesso: "Appunti ed immagini dai miei viaggi nel mondo dei bit ed i suoi dintorni". E appellandomi a quel "ed i suoi dintorni", ogni tanto la faccio fuori dal vaso postando anche qualche scritto un pò più... più... come dire, "intimista".
Come diario invece del mio viaggio nel mondo dei bit, il blog non può che riflettere quanto mi accade lungo il cammino, quanto scopro, quanto imparo. E se all'inizio scrivevo per me stesso, per dare una forma ad una passione che mi prendeva dentro ma non trovava poi nessuna manifestazione, nessuna espressione, le cose nel corso di pochi mesi sono cambiate.
Lungo il cammino ho trovato altri che come me viaggiano, esplorano, scoprono, e curiosi si pongono domande, e curiosi cercano risposte: ho incontrato voi. :-D
A volte vi incontro nella tranquillità dei commenti ai post, altre volte nelle più fredde statistiche di consultazione dei post, altre volte nelle mail che arrivano all'indirizzo di posta dedicato al blog (lo trovate in fondo alla barra laterale sinistra). E quale che sia la forma, sono felice di sapervi in cammino insieme a me, anche solo per un brevissimo tragitto, di sapere che altri viaggiatori viaggiano, che passano di qua, che spesso trovano quello che cercano, che altre volte invece ripartono, con una direzione, uno spunto che prima non avevano.
Ho cercato perciò di scrivere sempre in modo semplice ed esaustivo (ci sarò riuscito?), non dando mai nulla per scontato, perché tutti potessero trovarvi informazioni comprensibili, alla mano. Niente cose da super guru, il primo dei neofiti sono io. E rileggendo gli ultimi post, mi sono reso conto però che stanno diventando sempre più un atto di fede.
Per far funzionare bene Linux con VirtualBox infatti (ad esempio per la condivisione cartelle oppure la compressione del disco rigido virtuale), molto spesso ci siamo addentrati insieme nei meandri di Linux. Ok, la cartina era buona, il viaggio spero sia stato comodo e senza troppi intoppi. Ma ogni post assomiglia sempre di più ad una ricetta: fai così, fai cosà e ottieni questo risultato. Con una differenza sostanziale: se nella ricetta vi dico "ora buttate gli spaghetti nell'acqua bollente", posso tranquillamente omettere di dirvi che vanno prima tolti dalla busta, con Linux no.
In ogni ricetta si danno per scontate un sacco di cose che fanno semplicemente già parte del bagaglio comune di conoscenze. Con Linux questo bagaglio di conoscenze pregresse manca, siamo pur sempre dei neofiti che arrivano da Windows, e mi chiedo come sia per chi viene da MacOS... se mai esista! ;-)
Diceva Michele Benvegnù: "Ci sono troppe differenze tra le varie distribuzioni linux, ci si perde la testa".
Rispondevo: "Si, in effetti Linux è davvero trasformista per chi come noi è abituato a Windows. Questo perché (usando una metafora), mentre Windows è stato costruito in un unico blocco di marmo, Linux è stato costruito come l'unione di tanti mattoncini Lego.
Risultato: ciò che in Windows ha un solo ed unico aspetto, in Linux può assumere tanti aspetti diversi. Abituati noi alle cose con unico aspetto, ci lasciamo abbagliare e confondere dalle apparenze. L'unico modo per superare la difficoltà è dare un'occhiata da vicino a quei mattoncini, fuor di metafora, agli elementi base di Linux che si ripetono seppur con varie sfumature in ogni distribuzione.
Compresi i mattoncini ed il modo di metterli insieme, le sfumature non saranno più una rottura di balle, anzi, diverranno il punto di forza di Linux. E ognuno andrà a cercarsi la distribuzione con la sfumatura che più gli si addice."
Ecco perché, per tutto quanto vi ho detto finora, penso sia arrivato il momento di iniziare un nuovo viaggio, di addentrarci, questa volta senza ricette precotte, in un nuovo campo: Linux. Vorrei accompagnarvi nei suoi meandri, farvelo vedere da vicino, farvi vedere il suo cuore, farvelo toccare mentre pulsa pompando vita in un modo nuovo di intendere il mondo, di intendere la vita.
Che dite, cominciamo? :-D
@:\>
In fondo questo blog, a dispetto dei suoi stessi post che sono in gran parte dedicati alla virtualizzazione ed a VirtualBox in particolare, non ha un argomento prefissato, se non quanto compreso nel sottotitolo del blog stesso: "Appunti ed immagini dai miei viaggi nel mondo dei bit ed i suoi dintorni". E appellandomi a quel "ed i suoi dintorni", ogni tanto la faccio fuori dal vaso postando anche qualche scritto un pò più... più... come dire, "intimista".
Come diario invece del mio viaggio nel mondo dei bit, il blog non può che riflettere quanto mi accade lungo il cammino, quanto scopro, quanto imparo. E se all'inizio scrivevo per me stesso, per dare una forma ad una passione che mi prendeva dentro ma non trovava poi nessuna manifestazione, nessuna espressione, le cose nel corso di pochi mesi sono cambiate.
Lungo il cammino ho trovato altri che come me viaggiano, esplorano, scoprono, e curiosi si pongono domande, e curiosi cercano risposte: ho incontrato voi. :-D
A volte vi incontro nella tranquillità dei commenti ai post, altre volte nelle più fredde statistiche di consultazione dei post, altre volte nelle mail che arrivano all'indirizzo di posta dedicato al blog (lo trovate in fondo alla barra laterale sinistra). E quale che sia la forma, sono felice di sapervi in cammino insieme a me, anche solo per un brevissimo tragitto, di sapere che altri viaggiatori viaggiano, che passano di qua, che spesso trovano quello che cercano, che altre volte invece ripartono, con una direzione, uno spunto che prima non avevano.
Ho cercato perciò di scrivere sempre in modo semplice ed esaustivo (ci sarò riuscito?), non dando mai nulla per scontato, perché tutti potessero trovarvi informazioni comprensibili, alla mano. Niente cose da super guru, il primo dei neofiti sono io. E rileggendo gli ultimi post, mi sono reso conto però che stanno diventando sempre più un atto di fede.
Per far funzionare bene Linux con VirtualBox infatti (ad esempio per la condivisione cartelle oppure la compressione del disco rigido virtuale), molto spesso ci siamo addentrati insieme nei meandri di Linux. Ok, la cartina era buona, il viaggio spero sia stato comodo e senza troppi intoppi. Ma ogni post assomiglia sempre di più ad una ricetta: fai così, fai cosà e ottieni questo risultato. Con una differenza sostanziale: se nella ricetta vi dico "ora buttate gli spaghetti nell'acqua bollente", posso tranquillamente omettere di dirvi che vanno prima tolti dalla busta, con Linux no.
In ogni ricetta si danno per scontate un sacco di cose che fanno semplicemente già parte del bagaglio comune di conoscenze. Con Linux questo bagaglio di conoscenze pregresse manca, siamo pur sempre dei neofiti che arrivano da Windows, e mi chiedo come sia per chi viene da MacOS... se mai esista! ;-)
Diceva Michele Benvegnù: "Ci sono troppe differenze tra le varie distribuzioni linux, ci si perde la testa".
Rispondevo: "Si, in effetti Linux è davvero trasformista per chi come noi è abituato a Windows. Questo perché (usando una metafora), mentre Windows è stato costruito in un unico blocco di marmo, Linux è stato costruito come l'unione di tanti mattoncini Lego.
Risultato: ciò che in Windows ha un solo ed unico aspetto, in Linux può assumere tanti aspetti diversi. Abituati noi alle cose con unico aspetto, ci lasciamo abbagliare e confondere dalle apparenze. L'unico modo per superare la difficoltà è dare un'occhiata da vicino a quei mattoncini, fuor di metafora, agli elementi base di Linux che si ripetono seppur con varie sfumature in ogni distribuzione.
Compresi i mattoncini ed il modo di metterli insieme, le sfumature non saranno più una rottura di balle, anzi, diverranno il punto di forza di Linux. E ognuno andrà a cercarsi la distribuzione con la sfumatura che più gli si addice."
Ecco perché, per tutto quanto vi ho detto finora, penso sia arrivato il momento di iniziare un nuovo viaggio, di addentrarci, questa volta senza ricette precotte, in un nuovo campo: Linux. Vorrei accompagnarvi nei suoi meandri, farvelo vedere da vicino, farvi vedere il suo cuore, farvelo toccare mentre pulsa pompando vita in un modo nuovo di intendere il mondo, di intendere la vita.
Che dite, cominciamo? :-D
@:\>
venerdì 9 novembre 2007
VirtualBox: installazione di Ubuntu 7.10, suggerimenti
Nel post "VirtualBox e Ubuntu 7.10: matrimonio possibile" vi avevo raccontato delle difficoltà per virtualizzare Ubuntu 7.10 purtroppo condivise anche da alcuni di voi. Augusto segnalava un pò di quelli che ha avuto lui, insieme a qualche utile suggerimenti su come risolverli che riporto qui sotto.
Dunque in merito al noto problema della risoluzione video, le tecniche che sono state esposte nei precedenti post non hanno funzionato per la mia macchina quindi ho escogitato un trucchetto banale: ho spostato i panel a destra e sinistra del desktop e questo consente di vedere i pulsanti quel tanto che basta per usarli. Inoltre mi sono imbattuto nel problema del mirror: l'installazione cerca di connettersi probabilmente alla rete per qualche aggiornamento e se la connessione a internet dell'host non c'è oppure qualcosa ancora non va, bene li rimane (all'82%). Per risolverlo basta disconnettere la rete (durante la fase di installazione quando è bloccato), l'installer va in errore (ovviamente) e poi prosegue normalmente. Spero che questa "avventura" sia utile a qualcuno.
Sicuramente Augusto, grazie. :-)
@:\>
Dunque in merito al noto problema della risoluzione video, le tecniche che sono state esposte nei precedenti post non hanno funzionato per la mia macchina quindi ho escogitato un trucchetto banale: ho spostato i panel a destra e sinistra del desktop e questo consente di vedere i pulsanti quel tanto che basta per usarli. Inoltre mi sono imbattuto nel problema del mirror: l'installazione cerca di connettersi probabilmente alla rete per qualche aggiornamento e se la connessione a internet dell'host non c'è oppure qualcosa ancora non va, bene li rimane (all'82%). Per risolverlo basta disconnettere la rete (durante la fase di installazione quando è bloccato), l'installer va in errore (ovviamente) e poi prosegue normalmente. Spero che questa "avventura" sia utile a qualcuno.
Sicuramente Augusto, grazie. :-)
@:\>
lunedì 5 novembre 2007
VirtualBox: compattare dischi virtuali ad espansione dinamica - guest Linux (4a parte)
Aggiornamento: il post resta validissimo per la comprensione tecnica del problema pertanto continuo a consigliarne la lettura, ma al momento di procedere è senz'altro più semplice usare CloneVDI.
_________________________________________________________________________
Nella 3a parte del post sull'argomento avevamo visto come compilare zerofree, il programma per mettere a zero i blocchi liberi del disco rigido della macchina virtuale Linux, cosa indispensabile per poter poi procedere alla sua compattazione con il comando modifyvdi di VirtualBox. Come esempio avevamo usato una distribuzione Ubuntu, ed il programma così ottenuto dalla compilazione è già pronto per essere usato in qualunque altra distribuzione.
E se non avete installata una Ubuntu come fare a compilare il programma? Proprio questo è l'argomento del post: come compilare zerofree in una generica distribuzione Linux, e quali sono le eventuali difficoltà che potete incontrare sia nella compilazione che nel suo uso. Distribuzione di esempio, una Mandriva. Accendete la vostra macchina virtuale e iniziamo.
Un'avvertenza: quando lavoreremo nella shell, questa volta al posto di immagini troverete direttamente il copia-incolla del testo, così se non avete voglia di digitarvelo a manina (cosa sempre consigliata per dare un taglio più concreto alle cose) potete semplicemente copiarlo dal post e incollarlo nella vosta shell. Inoltre il risultato del comando è preceduto sempre da "$".
Do per scontato che abbiate già scaricato sul vostro desktop il sorgente del programma (fate riferimento alla 3a parte del post per i particolari), ora aprite la finestra della shell (si chiama Konsole se state usando l'interfaccia grafica KDE, Terminale se usate Gnome). Date i seguenti comandi per portarvi nella directory del vostro Desktop (tradotto in Scrivania nelle distribuzioni più recenti) e visualizzarne il contenuto:
Eccolo la il nostro sorgente: zerofree-1.0.1.tgz.
E' in formato tgz, detto più comunemente “tarball”, un formato tipico di Linux ottenuto in 2 fasi: raccogliendo più file in un unico file tramite il comando tar e poi sottoponendolo a compressione tramite gzip. Decomprimiamolo con il comando:
Come potete vedere, ha creato una directory zerofree-1.0.1 (la seconda riga) e dentro ha creato tre file: zerofree.c è il sorgente C del programma che poi compileremo, Makefile contiene le istruzione che vengono passate al compilatore quando daremo il comando make di compilazione. Portiamoci nella nuova directory e guardiamone il contenuto:
Eccoli là i nostri tre file; diamo il comando make di compilazione:
Come avevo preannunziato, questa volta non vi avrei risparmiato gli errori che si ottengono quando si prova a compilare zerofree, ed ecco il primo: il programma make (ricordate dal post sull'architettura di base di Linux? In Linux tutto è un programma, anche i comandi) non esiste (make: command not found), dobbiamo installarlo. In Mandriva si tratta di usare Installa e rimuovi software (fig. 1), ma ogni distribuzione Linux ha qualcosa di analogo, cercate e avviate questa funzione.
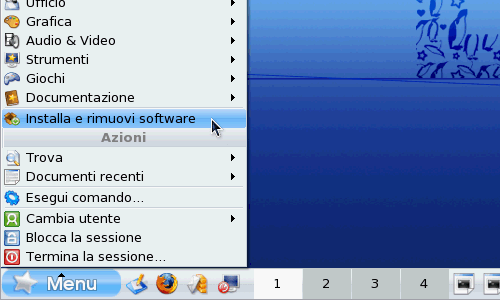
fig. 1
Usando il box Cerca (e l'analogo in altre distribuzioni) cerchiamo nei nomi la stringa "make": spuntate il relativo box e installatelo (fig. 2).
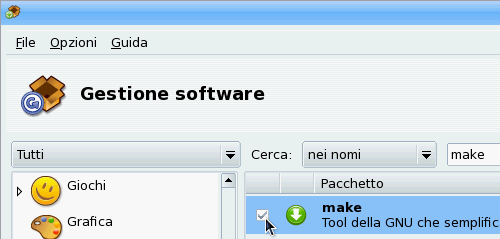
fig. 2
Lasciate aperta questa finestra e tornate alla shell, qui ridate il comando make:
Ora make c'è ed infatti compaiono nuove righe. La terza riga in particolare, quella subito sotto al comando make, lancia il compilatore (gcc) con una serie di parametri, peccato che gcc manchi (make: gcc: Command not found): installiamolo. Tornate nuovamente alla finestra di Gestione software e questa volta cercate con la stringa “gcc”; spuntate ed installate il relativo pacchetto (fig. 3).
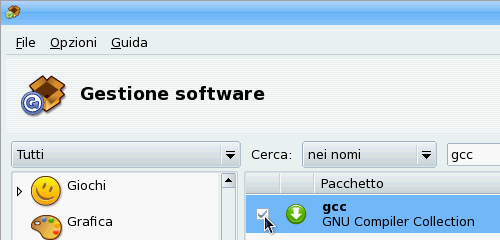
fig. 3
Lasciate la finestra aperta e tornate alla shell, ridate nuovamente il comando make:
Niente, errore anche questa volta, ma guardate con attenzione la terza riga: l'errore è cambiato. Ora cerca qualcosa che si chiama ext2fs e ext2fs.h. Torniamo alla finestra di Gestione software e cerchiamo il termine "ext2fs" (fig. 4). Quando trovate più pacchetti che rispondono alla stessa stringa di ricerca, tenete presente che stiamo cercando di compilare un'applicazione: il pacchetto di supporto alla compilazione nel nome ha sempre qualcosa come "dev" oppure "devel" (development = sviluppo, ricordatelo perché è una convenzione usata in Linux). Spuntate il pacchetto giusto è installatelo.
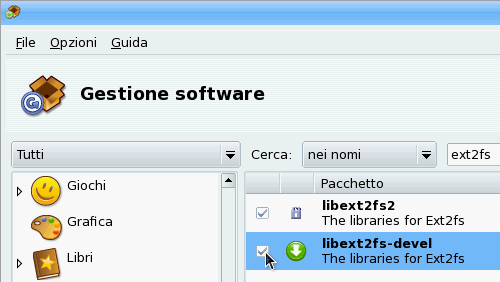
fig 4
Terminata l'installazione ritornate alla shell ridando il comando make:
Bravissimi!! La compilazione è andata a buon fine, ed il comando ls per vedere il contenuto della directory in cui vi trovate ci dice che esiste un nuovo file (ora sono quattro in tutto), zerofree, dove l'asterisco indica si tratta di un file eseguibile e non fa parte del nome. Copiamo adesso il programma nella directory /root , la home dell'amministratore:
chiudete ogni finestra aperta e nella shell date il comando:
In questo modo portate Linux al runlevel 1. I runlevel in Linux specificano cosa deve essere in funzione e cosa no per ognuno di essi; portarsi a runlevel 1 permette di rendere la macchina monoutente, tirar via tutto ciò che non serve per la sua amministrazione (interfaccia grafica, rete...) e lavorarci in tranquillità.
Se tutto è andato bene, vi ritroverete in una schermata simile a quella di fig. 5, dove ho dato un invio fra un comando e l'altro per aumentare la leggibilità. Cominciate con il notare che in questo momento siete amministratori della macchina (indicato dall'ultima lettera del prompt, # per l'amministratore e $ per l'utente normale), perciò attenti a quello che fate, potreste segarvi via l'intera distribuzione (non è un'esagerazione, può accadere con il comando giusto nel posto sbagliato).
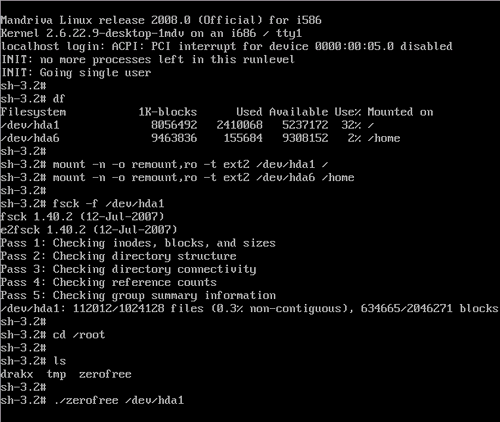
fig. 5
Ora, sempre guardando fig. 5, date il comando:
df permette di visualizzare dimensioni, spazio libero ed utilizzato di una data partizione, dato senza nessun argomento come sopra, ci mostra i dati di tutte le partizioni. In fig. 5 potete vedere come in Mandriva (e in tante altre distribuzioni) le cose siano un po' diverse da Ubuntu (fig. 8 della 3a parte del post per un confronto): le partizioni qui sono 2 e non una sola.
Nella prima riga della prima colonna infatti leggiamo che esiste un dispositivo (/dev = device) che corrisponde alla prima partizione del vostro disco rigido virtuale (/hda1), dopo un po' di dati sullo spazio occupato o meno, ci dice che è montato all'inizio del filesystem (estrema destra, la colonna “Mounted on” e sotto “/”).
Ma nella seconda riga della prima colonna leggiamo che esiste un altro dispositivo (/dev = device) che corrisponde all'altra partizione del vostro disco rigido virtuale (/hda6, perchè salti da a1 ad a6 lo si capirà in successivi post dedicati a Linux), e sempre dopo un po' di dati sullo spazio occupato o meno, ci dice che è montato su /home (estrema destra, la colonna “Mounted on” e sotto “/home”). In altre parole questa partizione contiene la vostra home.
La maggior parte delle distribuzioni, di default fanno proprio così: mettono su una partizione il sistema operativo, e su un'altra le home degli utenti. E' un po' come se sotto Windows sul disco C: installassimo solo Windows ed i programmi, e su D: invece la cartella Documenti (una prassi molto seguita in ambito aziendale). Che sia Windows o Linux, questa separazione è di grandissima utilità: potete in qualunque momento procedere ad una reinstallazione del sistema operativo senza la preoccupazione di perdere tutti i documenti che sono su una partizione separata (un salvataggio comunque è sempre consigliabile).
Torniamo a noi. Quello che ora faremo è rimontare le 2 partizioni in sola lettura, operazione indispensabile per procedere successivamente senza far danni. Date i comandi:
che tradotto significa: fai il mount, senza aggiornare il file mstab (-n), facendo il remount in sola lettura (remount,ro) come se fosse un filesystem di tipo EXT2 (-t ext2), del dispositivo /dev/hda1, rimontandolo in /; analogamente per il dispositivo /dev/hda6 rimontandolo in /home. Ora date il comando:
farete così un bel FileSystemChecK sulla prima partizione, un controllo approfondito per assicurarvi che tutto sia a posto prima di iniziare. Se riscontrasse dei problemi e vi propone dei rimedi, accettateli; a meno di essere dei “filesystem guru” non riuscireste a fare meglio di quanto propone. Quando ha terminato ed è tutto ok, date un bel
per portarvi nella home dell'amministratore. Ricordate? E' lì che abbiamo messo zerofree: è arrivato il momento di usarlo. Prima però verifichiamo se tutto è posto sui permessi di esecuzione del file. Date il comando
Se il risultato è qualcosa del tipo
le cose NON sono a posto. Le lettere vanno lette a gruppi di tre a partire dal secondo carattere e significano che il file:
- ha attivi i permessi di lettura/scrittura (rw, read write) per l'utente root;
- ha attivo il permesso di lettura (r) per il gruppo root;
- ha attivo il permesso di lettura (r) per tutti gli altri.
Per tutti manca il permesso di esecuzione del file (sarebbe una x alla terza lettera di ogni gruppo di tre, invece c'è - che significa la sua assenza), aggiungetelo per tutti con il comando:
poi verificate che adesso sia tutto a posto con
e dovreste avere qualcosa del tipo
con le x ad ogni terza lettera del gruppetto di tre. Ora potete finalmente eseguirlo con il comando:
Il comando dice a Linux di eseguire il programma zerofree cercandolo nella directory corrente (./) e di passare al programma la partizione su cui agire (/dev/hda1). Sembrerà che non accada nulla ma in realtà il programma sta lavorando intensamente; guardate l'icona di attività dei dischi rigidi virtuali, in basso a destra sulla barra di stato della finestra di VirtualBox che contiene il guest, e ve ne accorgerete. Quando zerofree avrà terminato il suo lavoro ricomparirà semplicemente il prompt: ridate il comando
per essere sicuri dell'integrità della partizione, e se tutto è ok abbiamo terminato con la prima partizione.
Ripetiamo gli stessi passi per l'altra partizione:
Qui fate attenzione: fsck si potrebbe lamentare come in fig. 6. In realtà il filesystem è montato in sola lettura proprio per evitare danni, per cui date y e proseguite.

fig. 6
Quando ha terminato:
e poi ancora
per essere sicuri che tutto sia a posto, infine spegnete la macchina virtuale con il comando:
Sul guest è tutto.
Ora che le zone libere del disco rigido virtuale sono state riempite di valori zero, sull'host non vi resta che dare il solito comando
ed avete terminato del tutto (per maggiori informazioni sul comando, leggete la parte finale della 1a parte del post). Ricordate solo che i doppi apici che racchiudono nomefile servono solo se nomefile contiene degli spazi, altrimenti potete ometterli.
Beh, direi proprio che potete fermarvi qui soddisfatti di quello che avete fatto. Intanto non avrete più problemi con dischi rigidi ad espansione dinamica che sanno solo espandersi: anche sotto Linux potrete comprimerli quando vi pare e con la massima efficacia. Non solo: avete imparato anche qualcosa in più sul funzionamento di Linux; ma qui, siamo solo all'inizio. ;-)
@:\>
_________________________________________________________________________
Nella 3a parte del post sull'argomento avevamo visto come compilare zerofree, il programma per mettere a zero i blocchi liberi del disco rigido della macchina virtuale Linux, cosa indispensabile per poter poi procedere alla sua compattazione con il comando modifyvdi di VirtualBox. Come esempio avevamo usato una distribuzione Ubuntu, ed il programma così ottenuto dalla compilazione è già pronto per essere usato in qualunque altra distribuzione.
E se non avete installata una Ubuntu come fare a compilare il programma? Proprio questo è l'argomento del post: come compilare zerofree in una generica distribuzione Linux, e quali sono le eventuali difficoltà che potete incontrare sia nella compilazione che nel suo uso. Distribuzione di esempio, una Mandriva. Accendete la vostra macchina virtuale e iniziamo.
Un'avvertenza: quando lavoreremo nella shell, questa volta al posto di immagini troverete direttamente il copia-incolla del testo, così se non avete voglia di digitarvelo a manina (cosa sempre consigliata per dare un taglio più concreto alle cose) potete semplicemente copiarlo dal post e incollarlo nella vosta shell. Inoltre il risultato del comando è preceduto sempre da "$".
Do per scontato che abbiate già scaricato sul vostro desktop il sorgente del programma (fate riferimento alla 3a parte del post per i particolari), ora aprite la finestra della shell (si chiama Konsole se state usando l'interfaccia grafica KDE, Terminale se usate Gnome). Date i seguenti comandi per portarvi nella directory del vostro Desktop (tradotto in Scrivania nelle distribuzioni più recenti) e visualizzarne il contenuto:
cd Scrivania
ls
$ Cartella condivisa host/ media.desktop trash.desktop zerofree-1.0.1.tgz Home.desktop register.desktop upgrade.desktopEccolo la il nostro sorgente: zerofree-1.0.1.tgz.
E' in formato tgz, detto più comunemente “tarball”, un formato tipico di Linux ottenuto in 2 fasi: raccogliendo più file in un unico file tramite il comando tar e poi sottoponendolo a compressione tramite gzip. Decomprimiamolo con il comando:
tar -xvzf zerofree-1.0.1.tgz
$ zerofree-1.0.1/
$ zerofree-1.0.1/zerofree.c
$ zerofree-1.0.1/COPYING
$ zerofree-1.0.1/MakefileCome potete vedere, ha creato una directory zerofree-1.0.1 (la seconda riga) e dentro ha creato tre file: zerofree.c è il sorgente C del programma che poi compileremo, Makefile contiene le istruzione che vengono passate al compilatore quando daremo il comando make di compilazione. Portiamoci nella nuova directory e guardiamone il contenuto:
cd zerofree-1.0.1
ls
$ COPYING Makefile zerofree.cEccoli là i nostri tre file; diamo il comando make di compilazione:
make
$ bash: make: command not foundCome avevo preannunziato, questa volta non vi avrei risparmiato gli errori che si ottengono quando si prova a compilare zerofree, ed ecco il primo: il programma make (ricordate dal post sull'architettura di base di Linux? In Linux tutto è un programma, anche i comandi) non esiste (make: command not found), dobbiamo installarlo. In Mandriva si tratta di usare Installa e rimuovi software (fig. 1), ma ogni distribuzione Linux ha qualcosa di analogo, cercate e avviate questa funzione.
fig. 1
Usando il box Cerca (e l'analogo in altre distribuzioni) cerchiamo nei nomi la stringa "make": spuntate il relativo box e installatelo (fig. 2).
fig. 2
Lasciate aperta questa finestra e tornate alla shell, qui ridate il comando make:
make
$ gcc -o zerofree -lext2fs zerofree.c
$ make: gcc: Command not found
$ make: *** [all] Error 127Ora make c'è ed infatti compaiono nuove righe. La terza riga in particolare, quella subito sotto al comando make, lancia il compilatore (gcc) con una serie di parametri, peccato che gcc manchi (make: gcc: Command not found): installiamolo. Tornate nuovamente alla finestra di Gestione software e questa volta cercate con la stringa “gcc”; spuntate ed installate il relativo pacchetto (fig. 3).
fig. 3
Lasciate la finestra aperta e tornate alla shell, ridate nuovamente il comando make:
>>gcc -o zerofree -lext2fs zerofree.c
$ zerofree.c:15:27: error: ext2fs/ext2fs.h: No such file or directory
$ zerofree.c: In function ‘main’:
$ zerofree.c:24: error: ‘errcode_t’ undeclared (first use in this function)
$ zerofree.c:24: error: (Each undeclared identifier is reported only once
$ zerofree.c:24: error: for each function it appears in.)
$ zerofree.c:24: error: expected ‘;’ before ‘ret’
[...]Niente, errore anche questa volta, ma guardate con attenzione la terza riga: l'errore è cambiato. Ora cerca qualcosa che si chiama ext2fs e ext2fs.h. Torniamo alla finestra di Gestione software e cerchiamo il termine "ext2fs" (fig. 4). Quando trovate più pacchetti che rispondono alla stessa stringa di ricerca, tenete presente che stiamo cercando di compilare un'applicazione: il pacchetto di supporto alla compilazione nel nome ha sempre qualcosa come "dev" oppure "devel" (development = sviluppo, ricordatelo perché è una convenzione usata in Linux). Spuntate il pacchetto giusto è installatelo.
fig 4
Terminata l'installazione ritornate alla shell ridando il comando make:
make
$ gcc -o zerofree -lext2fs zerofree.c
ls
COPYING Makefile zerofree* zerofree.cBravissimi!! La compilazione è andata a buon fine, ed il comando ls per vedere il contenuto della directory in cui vi trovate ci dice che esiste un nuovo file (ora sono quattro in tutto), zerofree, dove l'asterisco indica si tratta di un file eseguibile e non fa parte del nome. Copiamo adesso il programma nella directory /root , la home dell'amministratore:
sudo cp zerofree /root$ Parola d'ordine:chiudete ogni finestra aperta e nella shell date il comando:
sudo telinit 1In questo modo portate Linux al runlevel 1. I runlevel in Linux specificano cosa deve essere in funzione e cosa no per ognuno di essi; portarsi a runlevel 1 permette di rendere la macchina monoutente, tirar via tutto ciò che non serve per la sua amministrazione (interfaccia grafica, rete...) e lavorarci in tranquillità.
Se tutto è andato bene, vi ritroverete in una schermata simile a quella di fig. 5, dove ho dato un invio fra un comando e l'altro per aumentare la leggibilità. Cominciate con il notare che in questo momento siete amministratori della macchina (indicato dall'ultima lettera del prompt, # per l'amministratore e $ per l'utente normale), perciò attenti a quello che fate, potreste segarvi via l'intera distribuzione (non è un'esagerazione, può accadere con il comando giusto nel posto sbagliato).
fig. 5
Ora, sempre guardando fig. 5, date il comando:
dfdf permette di visualizzare dimensioni, spazio libero ed utilizzato di una data partizione, dato senza nessun argomento come sopra, ci mostra i dati di tutte le partizioni. In fig. 5 potete vedere come in Mandriva (e in tante altre distribuzioni) le cose siano un po' diverse da Ubuntu (fig. 8 della 3a parte del post per un confronto): le partizioni qui sono 2 e non una sola.
Nella prima riga della prima colonna infatti leggiamo che esiste un dispositivo (/dev = device) che corrisponde alla prima partizione del vostro disco rigido virtuale (/hda1), dopo un po' di dati sullo spazio occupato o meno, ci dice che è montato all'inizio del filesystem (estrema destra, la colonna “Mounted on” e sotto “/”).
Ma nella seconda riga della prima colonna leggiamo che esiste un altro dispositivo (/dev = device) che corrisponde all'altra partizione del vostro disco rigido virtuale (/hda6, perchè salti da a1 ad a6 lo si capirà in successivi post dedicati a Linux), e sempre dopo un po' di dati sullo spazio occupato o meno, ci dice che è montato su /home (estrema destra, la colonna “Mounted on” e sotto “/home”). In altre parole questa partizione contiene la vostra home.
La maggior parte delle distribuzioni, di default fanno proprio così: mettono su una partizione il sistema operativo, e su un'altra le home degli utenti. E' un po' come se sotto Windows sul disco C: installassimo solo Windows ed i programmi, e su D: invece la cartella Documenti (una prassi molto seguita in ambito aziendale). Che sia Windows o Linux, questa separazione è di grandissima utilità: potete in qualunque momento procedere ad una reinstallazione del sistema operativo senza la preoccupazione di perdere tutti i documenti che sono su una partizione separata (un salvataggio comunque è sempre consigliabile).
Torniamo a noi. Quello che ora faremo è rimontare le 2 partizioni in sola lettura, operazione indispensabile per procedere successivamente senza far danni. Date i comandi:
mount -n -o remount,ro -t ext2 /dev/hda1 /
mount -n -o remount,ro -t ext2 /dev/hda6 /homeche tradotto significa: fai il mount, senza aggiornare il file mstab (-n), facendo il remount in sola lettura (remount,ro) come se fosse un filesystem di tipo EXT2 (-t ext2), del dispositivo /dev/hda1, rimontandolo in /; analogamente per il dispositivo /dev/hda6 rimontandolo in /home. Ora date il comando:
fsck -f /dev/hda1farete così un bel FileSystemChecK sulla prima partizione, un controllo approfondito per assicurarvi che tutto sia a posto prima di iniziare. Se riscontrasse dei problemi e vi propone dei rimedi, accettateli; a meno di essere dei “filesystem guru” non riuscireste a fare meglio di quanto propone. Quando ha terminato ed è tutto ok, date un bel
cd /rootper portarvi nella home dell'amministratore. Ricordate? E' lì che abbiamo messo zerofree: è arrivato il momento di usarlo. Prima però verifichiamo se tutto è posto sui permessi di esecuzione del file. Date il comando
ls -lSe il risultato è qualcosa del tipo
-rw-r--r-- 1 root rootle cose NON sono a posto. Le lettere vanno lette a gruppi di tre a partire dal secondo carattere e significano che il file:
- ha attivi i permessi di lettura/scrittura (rw, read write) per l'utente root;
- ha attivo il permesso di lettura (r) per il gruppo root;
- ha attivo il permesso di lettura (r) per tutti gli altri.
Per tutti manca il permesso di esecuzione del file (sarebbe una x alla terza lettera di ogni gruppo di tre, invece c'è - che significa la sua assenza), aggiungetelo per tutti con il comando:
chmod +x zerofreepoi verificate che adesso sia tutto a posto con
ls -le dovreste avere qualcosa del tipo
-rwxr-xr-x 1 root root ...con le x ad ogni terza lettera del gruppetto di tre. Ora potete finalmente eseguirlo con il comando:
./zerofree /dev/hda1Il comando dice a Linux di eseguire il programma zerofree cercandolo nella directory corrente (./) e di passare al programma la partizione su cui agire (/dev/hda1). Sembrerà che non accada nulla ma in realtà il programma sta lavorando intensamente; guardate l'icona di attività dei dischi rigidi virtuali, in basso a destra sulla barra di stato della finestra di VirtualBox che contiene il guest, e ve ne accorgerete. Quando zerofree avrà terminato il suo lavoro ricomparirà semplicemente il prompt: ridate il comando
fsck -f /dev/hda1per essere sicuri dell'integrità della partizione, e se tutto è ok abbiamo terminato con la prima partizione.
Ripetiamo gli stessi passi per l'altra partizione:
fsck -f /dev/hda6Qui fate attenzione: fsck si potrebbe lamentare come in fig. 6. In realtà il filesystem è montato in sola lettura proprio per evitare danni, per cui date y e proseguite.
fig. 6
Quando ha terminato:
./zerofree /dev/hda6e poi ancora
fsck -f /dev/hda6per essere sicuri che tutto sia a posto, infine spegnete la macchina virtuale con il comando:
haltSul guest è tutto.
Ora che le zone libere del disco rigido virtuale sono state riempite di valori zero, sull'host non vi resta che dare il solito comando
“C:\Programmi\innotek VirtualBox\VBoxManage" modifyvdi “nomefile”.vdi compacted avete terminato del tutto (per maggiori informazioni sul comando, leggete la parte finale della 1a parte del post). Ricordate solo che i doppi apici che racchiudono nomefile servono solo se nomefile contiene degli spazi, altrimenti potete ometterli.
Beh, direi proprio che potete fermarvi qui soddisfatti di quello che avete fatto. Intanto non avrete più problemi con dischi rigidi ad espansione dinamica che sanno solo espandersi: anche sotto Linux potrete comprimerli quando vi pare e con la massima efficacia. Non solo: avete imparato anche qualcosa in più sul funzionamento di Linux; ma qui, siamo solo all'inizio. ;-)
@:\>
venerdì 2 novembre 2007
Firefox: aggiornamento alla versione 2.0.0.9
Se ne parlava e ieri è arrivato l'aggiornamento all'aggiornamento di Firefox. No, non è un gioco di parole: effettivamente è l'aggiornamento al precedente aggiornamento. Infatti se il passaggio alla versione 2.0.0.8 di Firefox risolveva qualcosa come più di 200 diversi problemi, alla fine ci si è accorti che introduceva anche qualche nuovo problema non proprio da sottovalutare.
Personalmente ho già aggiornato e vi sto scrivendo proprio con Firefox 2.0.0.9: per ora sembra tutto ok, gira regolarmente e nessuno dei plugin di Firefox che uso (una quindicina in tutto) ha smesso di funzionare; consigliato.
@:\>
Personalmente ho già aggiornato e vi sto scrivendo proprio con Firefox 2.0.0.9: per ora sembra tutto ok, gira regolarmente e nessuno dei plugin di Firefox che uso (una quindicina in tutto) ha smesso di funzionare; consigliato.
@:\>
Linux: Ubuntu 7.10 è atterrato
"Capì che fin dal principio il nostro scopo non fu quello di evitare il Giorno dell'Installazione, ma solo quello di sopravvivere ad esso. Insieme. Linux aveva cercato di dirmelo, ma il mio subcosciente non voleva sentirlo".
(Libero adattamento dal film Terminator 3)
Ebbene si, alla fine è accaduto. Ieri sera alle 22.00 ora italiana, Ubuntu 7.10 ha ufficialmente toccato la superficie del mio Hard Disk. Niente virtualizzazione, niente Wubi, direttamente a contatto con l'hardware del mio portatile. Complimenti al pilota (immodestamente, il sottoscritto... lasciatemi il momento di autocelebrazione! :-D), l'atterraggio è stato morbido e senza scosse.
E complimenti al meraviglioso lavoro fatto da tante persone che hanno portato Linux (nelle sue varie incarnazioni, Ubuntu, Mandriva, openSUSE e così via) ad un livello di usabilità davvero notevole. Ricordo la prima volta che cercai di installare una distribuzione nell'ormai lontano anno 2002. Si trattava di una Mandrake (che poi unitasi a Conectiva divenne Mandriva) e lo ammetto: non ci capì nulla, c'erano problemi di compatibilità con il mio PC ed in fondo non sapevo neanche che farmene, così tornai al mio Windows.
In 5 anni le cose sono davvero cambiate tanto. L'installazione è stata facile quasi quanto quella Windows, e se non avessi avuto appunto Windows già installato e da preservare, sarebbe stata davvero altrettanto semplice: metti il CD, avvia l'installazione, toglilo quando ha finito, riavvia, usalo. L'hardware è stato riconosciuto tutto al primo colpo, wireless compreso, la cosa che più mi dava pensiero. Avevo letto infatti di problemi con la connessione internet, ma non avevo approfondito, inutile farlo prima di avere il problema che infatti non c'è stato.
In questo momento vi sto scrivendo usando proprio Linux e Firefox, e devo dire che il periodo di acclimatamento nel virtualizzatore è stato molto utile. E nonostante ciò un momento di smarrimento c'è stato. Pensieri del tipo: oddio... e ora che faccio? Tolgo Windows? Lo lascio? Provo anche qualche altra distribuzione prima di affezionarmi ad una in particolare (chi ha detto Mandriva)? E la virtualizzazione?
Niente paura... una cosa certa è che con la virtualizzazione si va avanti e con nuovi argomenti. Se infatti VirtualBox (di cui continuerò a parlarvi) vi è piaciuto, quello che ora ho in mente è molto diverso, e molto più potente. State pensando a VMWare? Sbagliato! Ma ci sarà tempo di riparlarne.
E naturalmente ora ci sarà più spazio per Linux potendo apprezzare ed usare cose che in VirtualBox non erano possibili (virtualizzazione lato Linux prima di tutto ;-D). L'ottica dei post resterà la solita, quella dell'utente Windows che si aggira curioso fra i meandri di Linux desideroso di capire e far suo qualcosa di nuovo, il tutto con il solito corredo di immagini che il saggio diceva valgono più di mille parole (e qui mi devo attrezzare trovando in Linux l'analogo dei programmi che uso in Windows).
Bene, mi sembra tutto per ora, ma ci si rivede presto, molto presto! :-)
@:\>
(Libero adattamento dal film Terminator 3)
Ebbene si, alla fine è accaduto. Ieri sera alle 22.00 ora italiana, Ubuntu 7.10 ha ufficialmente toccato la superficie del mio Hard Disk. Niente virtualizzazione, niente Wubi, direttamente a contatto con l'hardware del mio portatile. Complimenti al pilota (immodestamente, il sottoscritto... lasciatemi il momento di autocelebrazione! :-D), l'atterraggio è stato morbido e senza scosse.
E complimenti al meraviglioso lavoro fatto da tante persone che hanno portato Linux (nelle sue varie incarnazioni, Ubuntu, Mandriva, openSUSE e così via) ad un livello di usabilità davvero notevole. Ricordo la prima volta che cercai di installare una distribuzione nell'ormai lontano anno 2002. Si trattava di una Mandrake (che poi unitasi a Conectiva divenne Mandriva) e lo ammetto: non ci capì nulla, c'erano problemi di compatibilità con il mio PC ed in fondo non sapevo neanche che farmene, così tornai al mio Windows.
In 5 anni le cose sono davvero cambiate tanto. L'installazione è stata facile quasi quanto quella Windows, e se non avessi avuto appunto Windows già installato e da preservare, sarebbe stata davvero altrettanto semplice: metti il CD, avvia l'installazione, toglilo quando ha finito, riavvia, usalo. L'hardware è stato riconosciuto tutto al primo colpo, wireless compreso, la cosa che più mi dava pensiero. Avevo letto infatti di problemi con la connessione internet, ma non avevo approfondito, inutile farlo prima di avere il problema che infatti non c'è stato.
In questo momento vi sto scrivendo usando proprio Linux e Firefox, e devo dire che il periodo di acclimatamento nel virtualizzatore è stato molto utile. E nonostante ciò un momento di smarrimento c'è stato. Pensieri del tipo: oddio... e ora che faccio? Tolgo Windows? Lo lascio? Provo anche qualche altra distribuzione prima di affezionarmi ad una in particolare (chi ha detto Mandriva)? E la virtualizzazione?
Niente paura... una cosa certa è che con la virtualizzazione si va avanti e con nuovi argomenti. Se infatti VirtualBox (di cui continuerò a parlarvi) vi è piaciuto, quello che ora ho in mente è molto diverso, e molto più potente. State pensando a VMWare? Sbagliato! Ma ci sarà tempo di riparlarne.
E naturalmente ora ci sarà più spazio per Linux potendo apprezzare ed usare cose che in VirtualBox non erano possibili (virtualizzazione lato Linux prima di tutto ;-D). L'ottica dei post resterà la solita, quella dell'utente Windows che si aggira curioso fra i meandri di Linux desideroso di capire e far suo qualcosa di nuovo, il tutto con il solito corredo di immagini che il saggio diceva valgono più di mille parole (e qui mi devo attrezzare trovando in Linux l'analogo dei programmi che uso in Windows).
Bene, mi sembra tutto per ora, ma ci si rivede presto, molto presto! :-)
@:\>
Iscriviti a:
Post (Atom)