Vi è capitato di eseguire un cron che svolge del lavoro per voi e voler salvarne l'output su un file che abbia come nome la data e l'ora (timestamp) di esecuzione, ma non funziona? Dopo aver dato un bel crontab -e basta scrivere così:
Perché funzioni è infatti fondamentale fare l'escaping dei simboli di percentuale "%" aggiungendo il backslash davanti, così: "\%".
Visualizzazione post con etichetta Amministrazione Linux. Mostra tutti i post
Visualizzazione post con etichetta Amministrazione Linux. Mostra tutti i post
lunedì 22 agosto 2016
giovedì 23 luglio 2015
Inserire caratteri unicode da tastiera
Per inserire direttamente il codice unicode di un carattere, gli utenti Windows usano la combinazione di tasti:
ALT + numero sul tastierino numerico.
Per gli utenti Linux la combinazione per inserire caratteri unicode da tastiera è leggermente più articolata:
Ctrl + Maiusc + u
Compare una u, basta scrivere il codice unicode (ad esempio 213b) e dare invio, in questo caso otteniamo il simbolo ℻.
La cosa funziona sicuramente con interfacce basate su GTK, ad esempio Gnome, su altre basate per esempio su KDE non ho verificato.
Sempre per gli utenti Linux, c'è comunque la possibilità di inserire virgolette alte, basse, singole, doppie, la tilde e così via, direttamente tramite queste combinazione di tasti.
ALT + numero sul tastierino numerico.
Per gli utenti Linux la combinazione per inserire caratteri unicode da tastiera è leggermente più articolata:
Ctrl + Maiusc + u
Compare una u, basta scrivere il codice unicode (ad esempio 213b) e dare invio, in questo caso otteniamo il simbolo ℻.
La cosa funziona sicuramente con interfacce basate su GTK, ad esempio Gnome, su altre basate per esempio su KDE non ho verificato.
Sempre per gli utenti Linux, c'è comunque la possibilità di inserire virgolette alte, basse, singole, doppie, la tilde e così via, direttamente tramite queste combinazione di tasti.
martedì 21 luglio 2015
CentOS: installazione ifconfig
Sopratutto nella versione Minimal di CentOS è da considerarsi normale che ifconfig non sia installato di default, in fondo il suo uso è deprecato a favore di ip.
In realtà è tutta la suite di programmi di net-tools a essere considerata obsoleta e sostituita per lo più da ip, ma anche da altri programmi contenuti all'interno di iproute2.
Volendo comunque usarlo, basta installare ifconfig con:
# yum -y install net-tools
In realtà è tutta la suite di programmi di net-tools a essere considerata obsoleta e sostituita per lo più da ip, ma anche da altri programmi contenuti all'interno di iproute2.
Volendo comunque usarlo, basta installare ifconfig con:
# yum -y install net-tools
lunedì 20 luglio 2015
Yum: rimuovere i pacchetti senza rimuovere le dipendenze
Per rimuovere una serie di pacchetti, in questo caso quelli del database PostgreSQL versione 9.4,
# yum erase postgresql94*
# yum erase postgresql94*
===================================================================================
Package Arch Versione Repository Dim.
===================================================================================
Rimozione in corso:
postgresql94 x86_64 9.4.4-1PGDG.rhel7 @pgdg94 5.4 M
postgresql94-contrib x86_64 9.4.4-1PGDG.rhel7 @pgdg94 2.1 M
postgresql94-libs x86_64 9.4.4-1PGDG.rhel7 @pgdg94 650 k
postgresql94-server x86_64 9.4.4-1PGDG.rhel7 @pgdg94 16 M
Rimozioni per dipendenze:
barman noarch 1.4.1-1.rhel7 @pgdg94 642 k
python-psycopg2 x86_64 2.6-1.rhel7 @pgdg94 433 k
Riepilogo della transazione
===================================================================================
Remove 4 Pacchetto (+2 Pacchetti dipendenti)
Dimensione installata: 26 M
senza rimuovere i pacchetti delle dipendenze (barman e python-psycopg2 evidenziati in grassetto) si può usare direttamente rpm:
# rpm -e --nodeps postgresql94-contrib postgresql94-libs postgresql94-server
venerdì 17 luglio 2015
CentOS: installazione font TrueType Microsoft
Grazie ai progetti Microsoft's Core Fonts for the Web e Cleartype Fonts sono disponibile in formato TrueType i font proprietari Andale Mono, Arial, Arial Black, Comic Sans MS, Courier New, Georgia, Impact, Times New Roman, Trebuchet MS, Verdana and Webdings che permettono una visione dei documenti più uniforme su varie piattaforme anche non Windows.
Per installare i Microsoft's Core Fonts for the Web e Cleartype Fonts su CentOS:
# yum install curl cabextract xorg-x11-font-utils fontconfig
# rpm -i https://downloads.sourceforge.net/project/mscorefonts2/rpms/msttcore-fonts-installer-2.6-1.noarch.rpm
Per installare i Microsoft's Core Fonts for the Web e Cleartype Fonts su CentOS:
# yum install curl cabextract xorg-x11-font-utils fontconfig
# rpm -i https://downloads.sourceforge.net/project/mscorefonts2/rpms/msttcore-fonts-installer-2.6-1.noarch.rpm
giovedì 16 luglio 2015
CentOS: assegnare/modificare il nome host
Modifica dell'hostname su CentOS 5 e 6
Occorre modificare sia il file /etc/sysconfig/network che /etc/hosts.
Se non viene modificato anche il secondo, alcuni comandi ci mettono molto più tempo per l'esecuzione perché cercano di ricavare l'IP dell'host locale dal nome host. Senza una voce in /etc/hosts, si deve passare attraverso il processo di ricerca completo del nome prima di poter andare avanti. A seconda della configurazione del DNS questo può significare ritardi più o meno consistenti.
Dopo essersi loggati come amministratori, aprire il file /etc/sysconfig/network e inserire:
NETWORKING=yes
HOSTNAME=nome-host
Nel file /etc/hosts inserire:
indirizzo-ip nome-host
Ad esempio:
192.168.1.10 server1
Far ripartire la rete:
# service network restart
Modifica dell'hostname su CentOS 7
Qui le cose sono molto più semplici, è sufficiente
hostnamectl set-hostname nome-host
ed il nome è subito assegnato alla macchina senza fare altro.
mercoledì 15 luglio 2015
CentOS: assegnare un indirizzo IP statico
Stanchi di veder cambiare l'indirizzo IP assegnato dal DHCP alla vostra macchina CentOS? Assegnamogli un indirizzo IP statico usando NetworkManager text user interface (TUI):
# nmtui
Configurate la macchina sulla falsariga di Fig. 1:

Riavviate la macchina e verificate di avere l'indirizzo IP scelto:
$ ifconfig
enp0s9: flags=4163 mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.100
inet6 fe80::a00:27ff:fea1:c640 prefixlen 64 scopeid 0x20
ether 08:00:27:a1:c6:40 txqueuelen 1000 (Ethernet)
RX packets 31 bytes 3380 (3.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 55 bytes 6555 (6.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# nmtui
Configurate la macchina sulla falsariga di Fig. 1:

Figura 1: configurazione IP statico su CentOS con NetworkManager Text User Interface
Riavviate la macchina e verificate di avere l'indirizzo IP scelto:
$ ifconfig
enp0s9: flags=4163
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.100
inet6 fe80::a00:27ff:fea1:c640 prefixlen 64 scopeid 0x20
ether 08:00:27:a1:c6:40 txqueuelen 1000 (Ethernet)
RX packets 31 bytes 3380 (3.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 55 bytes 6555 (6.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
martedì 14 luglio 2015
CentOS: eliminare vecchi kernel
I kernel occupano spazio su disco, spazio che possiamo recuperare rimuovendo i kernel più vecchi e tenendo solo gli ultimi due:
Disinstallare i kernel più vecchi su CentOS è particolamente semplice.
La lista dei kernel attualmente installati:
# rpm -q kernel
kernel-3.10.0-229.el7.x86_64
kernel-3.10.0-229.1.2.el7.x86_64
kernel-3.10.0-229.4.2.el7.x86_64
kernel-3.10.0-229.7.2.el7.x86_64
Installazione di yum-utils, un tool per estendere la gestione dei package e dei repository di yum:
# yum install yum-utils
Fra gli strumenti forniti con yum-utils c'è il programma package-cleanup. Per eliminare tutti i kernel tranne i 2 più recenti:
# package-cleanup --oldkernels --count=2
Controllare che effettivamente siano rimasti i due kernel più recenti:
# rpm -q kernel
kernel-3.10.0-229.4.2.el7.x86_64
kernel-3.10.0-229.7.2.el7.x86_64
E per le prossime volte si può lasciare a yum il compito di tenere solo i due kernel più recenti. È sufficiente modificare il file /etc/yum.conf con:
installonly_limit=2
È tutto.
- quello attualmente in funzione;
- quello precedente come scorta, per avere un kernel funzionante a cui poter tornare nel caso quello attuale desse qualche problema.
Disinstallare i kernel più vecchi su CentOS è particolamente semplice.
La lista dei kernel attualmente installati:
# rpm -q kernel
kernel-3.10.0-229.el7.x86_64
kernel-3.10.0-229.1.2.el7.x86_64
kernel-3.10.0-229.4.2.el7.x86_64
kernel-3.10.0-229.7.2.el7.x86_64
Installazione di yum-utils, un tool per estendere la gestione dei package e dei repository di yum:
# yum install yum-utils
Fra gli strumenti forniti con yum-utils c'è il programma package-cleanup. Per eliminare tutti i kernel tranne i 2 più recenti:
# package-cleanup --oldkernels --count=2
Controllare che effettivamente siano rimasti i due kernel più recenti:
# rpm -q kernel
kernel-3.10.0-229.4.2.el7.x86_64
kernel-3.10.0-229.7.2.el7.x86_64
E per le prossime volte si può lasciare a yum il compito di tenere solo i due kernel più recenti. È sufficiente modificare il file /etc/yum.conf con:
installonly_limit=2
È tutto.
lunedì 13 luglio 2015
CentOS: installazione VirtualBox Guest Additions
Installazione delle VirtualBox Guest Additions in un guest CentOS.
Prima di tutto l'installazione degli strumenti di sviluppo necessari alla compilazione e al mantenimento delle VirtualBox Guest Additions:
# yum -y update kernel
# yum -y install kernel-devel kernel-headers dkms gcc gcc-c++ bzip2
Montare il CD-ROM delle Guest Additions dal menù Dispositivi | Inserisci l'immagine del CD delle Guest Additions... nella finestra del guest, attendere che si apra la finestra dell'autorun e cliccare su Esegui inserendo la password da amministratore quando richiesto.
Nel caso non ci sia l'interfaccia grafica, ad esempio nella versione Minimal di CentOS non l'avete ancora avviata e state lavorando da shell, il CD-ROM va montato a mano:
# mount /dev/cdrom /mnt
# sh /mnt/VBoxLinuxAdditions.run
Riavviate il sistema e avete finito.
Senza l'installazione del dkms, ad ogni aggiornamento del kernel le VirtualBox Guest Additions smetterebbero di funzionare (si perderebbe l'integrazione del mouse, maggiori risoluzioni video a dispozione, copia-incolla e così via), a volte accade anche se dkms è stato installato (dipende dal tipo di aggiornamento del kernel).
In questi casi:
# /etc/init.d/vboxadd setup
oppure
# service vboxadd setup
e le VirtualBox Guest Additions riprenderanno a funzionare.
Prima di tutto l'installazione degli strumenti di sviluppo necessari alla compilazione e al mantenimento delle VirtualBox Guest Additions:
# yum -y update kernel
# yum -y install kernel-devel kernel-headers dkms gcc gcc-c++ bzip2
Montare il CD-ROM delle Guest Additions dal menù Dispositivi | Inserisci l'immagine del CD delle Guest Additions... nella finestra del guest, attendere che si apra la finestra dell'autorun e cliccare su Esegui inserendo la password da amministratore quando richiesto.
Nel caso non ci sia l'interfaccia grafica, ad esempio nella versione Minimal di CentOS non l'avete ancora avviata e state lavorando da shell, il CD-ROM va montato a mano:
# mount /dev/cdrom /mnt
# sh /mnt/VBoxLinuxAdditions.run
Riavviate il sistema e avete finito.
Senza l'installazione del dkms, ad ogni aggiornamento del kernel le VirtualBox Guest Additions smetterebbero di funzionare (si perderebbe l'integrazione del mouse, maggiori risoluzioni video a dispozione, copia-incolla e così via), a volte accade anche se dkms è stato installato (dipende dal tipo di aggiornamento del kernel).
In questi casi:
# /etc/init.d/vboxadd setup
oppure
# service vboxadd setup
e le VirtualBox Guest Additions riprenderanno a funzionare.
venerdì 10 luglio 2015
CentOS 7 Minimal: installazione Xfce
CentOS 7 Minimal è appunto tale: minimale.
La prima cosa che non c'è di default è un ambiente desktop con la sua rassicurante (per alcuni) interfaccia grafica. Su una macchina server in genere la cosa è accettabile, in fondo si passa parte del tempo sulla linea di comando, su macchine con poca RAM è quasi una scelta obbligata.
Ci sono però occasioni in cui sarebbe davvero utile averne una. Mi capita spesso di lavorare con macchine virtuali su VirtualBox, e per motivi documentali vorrei poter fare il copia-incolla di comandi e messaggistica dall'host al guest e viceversa.
La cosa è possibile con le VirtualBox Guest Additions installate su un guest con interfaccia grafica. Le macchine virtuali però hanno appena 1 GB di Ram l'una, quindi serve un'interfaccia grafica leggera e funzionale: Xfce.
Per installare Xfce su CentOS 7 Minimal:
# yum -y install epel-release
# yum -y groupinstall "Xfce" "X Window system"
Per evitare in alcuni casi possibili messaggi di errore, vanno installati anche i seguenti pacchetti:
# yum -y install xorg-x11-fonts-Type1 xorg-x11-fonts-misc
Per un look-and-feel un po' più aggraziato:
# yum -y install faience-icon-theme
Se volete avere un terminale con cui continuare a lavorare da linea di comando anche una volta avviata l'interfaccia grafica di Xfce:
# yum install xfce4-terminal
Infine, per avviare Xfce:
# startxfce4
Al primo avvio (Fig. 1) viene chiesta la configurazione del pannello, cliccare su Utilizza la configurazione predefinita per proseguire:

Terminata la configurazione ecco finalmente Xfce pienamente funzionante (Fig. 2):

Per far partire CentOS 7 direttamente con l'interfaccia grafica di Xfce, settare come default il runlevel 5. Questo nella nuova gestione di Systemd è stato rimpiazzato con il concetto di target ed emulato tramite il target graphical.target:
# systemctl set-default graphical.target
Se poi si cambia idea, si può togliere la partenza automatica di Xfce all'avvio di CentOS 7 tornando al runlevel 3, ora emulato da multi-user.target:
# systemctl set-default multi-user.target
Giusto come curiosità il consumo di RAM prima di avviare Xfce in Fig. 3,

ed il consumo di RAM con Xfce avviato appena dopo l'installazione, quindi non appesantito da plugin:
$ free
total used free shared buff/cache available
Mem: 1017368 159892 609004 8432 248472 702244
Swap: 2097148 0 2097148
Il consumo di RAM rimane buono, la comodità per alcune attività aumenta, e quando l'interfaccia grafica non serve più basta cliccare in alto a destra sul proprio nome utente | Esci... | Esci e si torna alla shell liberando memoria.
La prima cosa che non c'è di default è un ambiente desktop con la sua rassicurante (per alcuni) interfaccia grafica. Su una macchina server in genere la cosa è accettabile, in fondo si passa parte del tempo sulla linea di comando, su macchine con poca RAM è quasi una scelta obbligata.
Ci sono però occasioni in cui sarebbe davvero utile averne una. Mi capita spesso di lavorare con macchine virtuali su VirtualBox, e per motivi documentali vorrei poter fare il copia-incolla di comandi e messaggistica dall'host al guest e viceversa.
La cosa è possibile con le VirtualBox Guest Additions installate su un guest con interfaccia grafica. Le macchine virtuali però hanno appena 1 GB di Ram l'una, quindi serve un'interfaccia grafica leggera e funzionale: Xfce.
Per installare Xfce su CentOS 7 Minimal:
# yum -y install epel-release
# yum -y groupinstall "Xfce" "X Window system"
Per evitare in alcuni casi possibili messaggi di errore, vanno installati anche i seguenti pacchetti:
# yum -y install xorg-x11-fonts-Type1 xorg-x11-fonts-misc
Per un look-and-feel un po' più aggraziato:
# yum -y install faience-icon-theme
Se volete avere un terminale con cui continuare a lavorare da linea di comando anche una volta avviata l'interfaccia grafica di Xfce:
# yum install xfce4-terminal
Infine, per avviare Xfce:
# startxfce4
Al primo avvio (Fig. 1) viene chiesta la configurazione del pannello, cliccare su Utilizza la configurazione predefinita per proseguire:

Figura 1: configurazione pannello al primo avvio
Terminata la configurazione ecco finalmente Xfce pienamente funzionante (Fig. 2):

Figura 2: configurazione Xfce completata.
Per far partire CentOS 7 direttamente con l'interfaccia grafica di Xfce, settare come default il runlevel 5. Questo nella nuova gestione di Systemd è stato rimpiazzato con il concetto di target ed emulato tramite il target graphical.target:
# systemctl set-default graphical.target
Se poi si cambia idea, si può togliere la partenza automatica di Xfce all'avvio di CentOS 7 tornando al runlevel 3, ora emulato da multi-user.target:
# systemctl set-default multi-user.target
Giusto come curiosità il consumo di RAM prima di avviare Xfce in Fig. 3,
Figura 3: consumo di RAM prima di avviare Xfce
ed il consumo di RAM con Xfce avviato appena dopo l'installazione, quindi non appesantito da plugin:
$ free
total used free shared buff/cache available
Mem: 1017368 159892 609004 8432 248472 702244
Swap: 2097148 0 2097148
Il consumo di RAM rimane buono, la comodità per alcune attività aumenta, e quando l'interfaccia grafica non serve più basta cliccare in alto a destra sul proprio nome utente | Esci... | Esci e si torna alla shell liberando memoria.
giovedì 9 luglio 2015
CentOS: aggiungere repository EPEL
EPEL (Extra Packages for Enterprise Linux) è un progetto avviato dalla comunità Fedora desiderosa di utilizzare i pacchetti di questa distribuzione anche sulle versioni Enterprise Linux, quindi Red Hat Enterprise Linux (RHEL) e derivate compatibili, in primis CentOS, Scientific Linux (SL) e Oracle Linux (OL).
I pacchetti di questo repository sono quindi basati (quasi sempre) sugli analoghi del progetto Fedora, e si affiancano (senza sostituirsi) a quelli già compresi nelle distribuzioni Enterprise Linux in versione, almeno attualmente, 7, 6, 5. In questo modo si ha più software tra cui scegliere anche per sistemi Enterprise Linux, con tutta la qualità che il supporto della comunità Fedora fornisce.
Per aggiungere i repository EPEL a CentOS:
# yum install epel-release
I pacchetti di questo repository sono quindi basati (quasi sempre) sugli analoghi del progetto Fedora, e si affiancano (senza sostituirsi) a quelli già compresi nelle distribuzioni Enterprise Linux in versione, almeno attualmente, 7, 6, 5. In questo modo si ha più software tra cui scegliere anche per sistemi Enterprise Linux, con tutta la qualità che il supporto della comunità Fedora fornisce.
Per aggiungere i repository EPEL a CentOS:
# yum install epel-release
mercoledì 8 luglio 2015
CentOS 7 Minimal: attivazione dell'autocompletamento nella shell Bash
Per installare l'autocompletamento nel terminale Bash di una CentOS 7 Minimal:
# yum -y install bash-completion
# yum -y install bash-completion
martedì 7 luglio 2015
CentOS 7 Minimal: configurare la rete
La fretta è sempre cattiva consigliera: durante l'installazione di CentOS 7 Minimal ho dimenticato di configurare la rete. Una volta terminata l'installazione si può però configurare la connessione di rete direttamente da terminale usando il NetworkManager.
Verificare lo stato della connessione da NetworkManager command-line interface (cli):
# nmcli d

Se lo stato è scollegato come in Fig. 1, la connessione va attivata usando per comodità il NetworkManager Text User Interface (TUI) che fornisce una interfaccia semigrafica più comoda da usare:
# nmtui
Apparirà la schermata di Fig. 2, dare Invio:

Spostarsi con Tab su Modifica come in Fig. 3:

Spostandosi sempre con il tasto Tab, assicurarsi che tutto sia come in Fig. 4, in particolare:

Quando è tutto correttamente configurato, con il tasto Tab portarsi su OK e dare Invio per salvare. Controllare che la connessione adesso sia attiva come in Fig. 5 con il comando:
#nmcli d

Se la connessione non fosse ancora attiva riavviare la rete:
# systemctl restart network.service
Se serve conoscere l'indirizzo IP assegnato automaticamente da DHCP all'host (in Fig. 6 evidenziato quello IPv4):
# ip addr

È tutto.
Verificare lo stato della connessione da NetworkManager command-line interface (cli):
# nmcli d

Figura 1: CentOS 7 Minimal, rete non configurata
Se lo stato è scollegato come in Fig. 1, la connessione va attivata usando per comodità il NetworkManager Text User Interface (TUI) che fornisce una interfaccia semigrafica più comoda da usare:
# nmtui
Apparirà la schermata di Fig. 2, dare Invio:

Figura 2: Network Manager per configurare la rete
Spostarsi con Tab su Modifica come in Fig. 3:

Figura 3: Network Manager modifica opzioni di connessione
Spostandosi sempre con il tasto Tab, assicurarsi che tutto sia come in Fig. 4, in particolare:
- la configurazione IPv4 e IPv6 sia impostata su Automatico così da avere l'indirizzo ip assegnato in automatico tramite DHCP;
- Connessione automatica sia selezionato con [X], altrimenti spostarsi con Tab e premere la barra spaziatrice per selezionare.

Figura 4: configurazione connessione di rete tramite DHCP
Quando è tutto correttamente configurato, con il tasto Tab portarsi su OK e dare Invio per salvare. Controllare che la connessione adesso sia attiva come in Fig. 5 con il comando:
#nmcli d

Figura 5: connessione di rete attiva
Se la connessione non fosse ancora attiva riavviare la rete:
# systemctl restart network.service
Se serve conoscere l'indirizzo IP assegnato automaticamente da DHCP all'host (in Fig. 6 evidenziato quello IPv4):
# ip addr
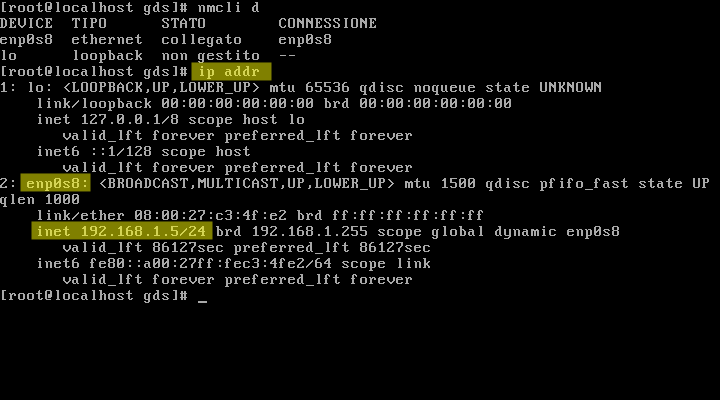
Figura 6: indirizzi ip (evidenziato IPv4) assegnati da DHCP all'host
È tutto.
lunedì 6 luglio 2015
Installazione di locate su CentOS Minimal
Una delle cose che mi manca su CentOS Minimal è la sua comodità e velocità. Per installare il comando locate:
$ su
# yum -y install mlocate
# yum updatedb
$ su
# yum -y install mlocate
# yum updatedb
venerdì 8 novembre 2013
Ubuntu: installazione di SQLite da sorgente
Prima o poi un database può servire, e serve un RDBMS per gestirlo. Una scelta molto comune è MySQL, altra possibile scelta è PostgreSQL, ma non sempre c'è bisogno di scomodare tanta potenza e peso.
A volte serve qualcosa di piccolo ed essenziale, facile da installare e da usare, che sia multipiattaforma e richieda poca o nessuna amministrazione, che possa essere usato sia come prodotto a se stante, sia gestito dall'interno dei nostri programmi scritti in un linguaggio di programmazione come C/Java/PHP/Python, e molti altri per cui esiste il binding.
Queste sono le occasioni in cui SQLite fa al caso nostro. Il prodotto ha notevoli possibilità e anche limiti, per cui è sempre da valutare con attenzione se fa proprio al caso nostro.
Vediamo come installarlo su una macchina Ubuntu partendo direttamente dai sorgenti disponibili per il dowload sul sito ufficiale. Per le prove ho usato una Ubuntu 12.04 LTS a 64 bit e SQLite 3, ma con piccole modifiche immagino sia una procedura del tutto generale. Fatemi sapere laddove doveste incontrare problemi, ma anche laddove è andato tutto bene.
Iniziamo con l'installazione preliminare dell'occorrente per la successiva compilazione dei sorgenti. Aprite un terminale e date il comando:
sudo apt-get install build-essential checkinstall
Scaricate dal link precedente il sorgente sqlite-autoconf-nomeversione.tar.gz, nel momento in cui scrivo il nome esatto del file è sqlite-autoconf-3080100.tar.gz., ma con il tempo la parte numerica cambierà in funzione delle nuove versioni, assicuratevi comunque che si tratti sempre del file con la stringa "autoconf" nel nome.
Portatevi con il terminale nella cartella dove avete scaricato il file e decomprimetelo con
tar xvfz sqlite-autoconf-3080100.tar.gz
poi compilatelo con:
cd sqlite-autoconf-3080100
./configure
make
sudo checkinstall
Se tutto procede bene, ad un certo punto "Checkinstall" vi chiederà:
The package documentation directory ./doc-pak does not exist.
Should I create a default set of package docs? [y]:
Rispondete y oppure n a seconda che vogliate o meno creare ed installare la documentazione del software. Vi verrà anche chiesto di inserire una descrizione del pacchetto:
Inserire una breve descrizione per il pacchetto.
Termina la tua descrizione con un linea vuota o EOF.
>>
Inseritene una a vostro piacimento, per esempio:
SQLite 3.8.1 installed from source with Checkinstall.
e date esattamente 3 volte "Invio" sulla tastiera per proseguire l'installazione. Una volta terminata, per testare il funzionamento di SQLite date il comando:
sqlite3
Se beccate l'errore
SQLite header and source version mismatch
allora c'è un problema di librerie non aggiornate dall'installazione da risolvere così:
sudo updatedb
locate libsqlite3
Vedrete che le librerie libsqlite3.so.0 e libsqlite3.so.0.8.6 sono presenti in almeno 3 directory:
/usr/lib/i386-linux-gnu/libsqlite3.so.0
/usr/lib/i386-linux-gnu/libsqlite3.so.0.8.6
/usr/lib/x86_64-linux-gnu/libsqlite3.a
/usr/lib/x86_64-linux-gnu/libsqlite3.la
/usr/lib/x86_64-linux-gnu/libsqlite3.so
/usr/lib/x86_64-linux-gnu/libsqlite3.so.0
/usr/lib/x86_64-linux-gnu/libsqlite3.so.0.8.6
/usr/local/lib/libsqlite3.a
/usr/local/lib/libsqlite3.la
/usr/local/lib/libsqlite3.so
/usr/local/lib/libsqlite3.so.0
/usr/local/lib/libsqlite3.so.0.8.6
Controllando le date (controllate effettivamente, non vorrei che proprio nel vostro caso i problemi fossero altri) si vedrà che i file delle directory usr/lib/i386-linux-gnu/ e /usr/lib/x86_64-linux-gnu/ non sono aggiornati alla stessa data di quelli nella directory /usr/local/lib/, i più recenti appena installati.
Su Ubuntu 64 bit è sufficiente aggiornare i file nella sola directory /usr/lib/x86_64-linux-gnu/ copiandovi quelli della directory /usr/local/lib/.
Immagino, ma NON ho testato l'ipotesi, che per installazioni di Ubuntu a 32 bit la directory /usr/lib/x86_64-linux-gnu/ va sostituita con la directory /usr/lib/i386-linux-gnu/.
Perché SQLite riprenda a funzionare è sufficiente aggiornare solo i 2 file libsqlite3.so.0 e libsqlite3.so.0.8.6, per mantenere il tutto allineato è preferibile aggiornarli tutti.
Per sicurezza è meglio cambiare nome ai file da aggiornare piuttosto che cancellarli o sovrascriverli, così da poter tornare indietro in caso di necessità:
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.a /usr/lib/x86_64-linux-gnu/libsqlite3.a_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.la /usr/lib/x86_64-linux-gnu/libsqlite3.la_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.so /usr/lib/x86_64-linux-gnu/libsqlite3.so_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.so.0 /usr/lib/x86_64-linux-gnu/libsqlite3.so.0_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.so.0.8.6 /usr/lib/x86_64-linux-gnu/libsqlite3.so.0.8.6_bak
Infine copiare i nuovi file al posto dei vecchi rinominati:
sudo cp /usr/local/lib/libsqlite3.a /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.la /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.so /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.so.0 /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.so.0.8.6 /usr/lib/x86_64-linux-gnu/
Se tutto è stato fatto correttamente ora SQLite dovrebbe funzionare. Provate a ridare il comando:
sqlite3
e SQLite dovrebbe rispondervi:
SQLite version 3.8.1 2013-10-17 12:57:35
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
>
Per uscire dal prompt e terminare SQLite:
.q
Per disinstallarlo completamente:
sudo apt-get remove --purge sqlite-autoconf
E' tutto... buon lavoro con SQLite!
A volte serve qualcosa di piccolo ed essenziale, facile da installare e da usare, che sia multipiattaforma e richieda poca o nessuna amministrazione, che possa essere usato sia come prodotto a se stante, sia gestito dall'interno dei nostri programmi scritti in un linguaggio di programmazione come C/Java/PHP/Python, e molti altri per cui esiste il binding.
Queste sono le occasioni in cui SQLite fa al caso nostro. Il prodotto ha notevoli possibilità e anche limiti, per cui è sempre da valutare con attenzione se fa proprio al caso nostro.
Vediamo come installarlo su una macchina Ubuntu partendo direttamente dai sorgenti disponibili per il dowload sul sito ufficiale. Per le prove ho usato una Ubuntu 12.04 LTS a 64 bit e SQLite 3, ma con piccole modifiche immagino sia una procedura del tutto generale. Fatemi sapere laddove doveste incontrare problemi, ma anche laddove è andato tutto bene.
Iniziamo con l'installazione preliminare dell'occorrente per la successiva compilazione dei sorgenti. Aprite un terminale e date il comando:
sudo apt-get install build-essential checkinstall
Scaricate dal link precedente il sorgente sqlite-autoconf-nomeversione.tar.gz, nel momento in cui scrivo il nome esatto del file è sqlite-autoconf-3080100.tar.gz., ma con il tempo la parte numerica cambierà in funzione delle nuove versioni, assicuratevi comunque che si tratti sempre del file con la stringa "autoconf" nel nome.
Portatevi con il terminale nella cartella dove avete scaricato il file e decomprimetelo con
tar xvfz sqlite-autoconf-3080100.tar.gz
poi compilatelo con:
cd sqlite-autoconf-3080100
./configure
make
sudo checkinstall
Se tutto procede bene, ad un certo punto "Checkinstall" vi chiederà:
The package documentation directory ./doc-pak does not exist.
Should I create a default set of package docs? [y]:
Rispondete y oppure n a seconda che vogliate o meno creare ed installare la documentazione del software. Vi verrà anche chiesto di inserire una descrizione del pacchetto:
Inserire una breve descrizione per il pacchetto.
Termina la tua descrizione con un linea vuota o EOF.
>>
Inseritene una a vostro piacimento, per esempio:
SQLite 3.8.1 installed from source with Checkinstall.
e date esattamente 3 volte "Invio" sulla tastiera per proseguire l'installazione. Una volta terminata, per testare il funzionamento di SQLite date il comando:
sqlite3
Se beccate l'errore
SQLite header and source version mismatch
allora c'è un problema di librerie non aggiornate dall'installazione da risolvere così:
sudo updatedb
locate libsqlite3
Vedrete che le librerie libsqlite3.so.0 e libsqlite3.so.0.8.6 sono presenti in almeno 3 directory:
/usr/lib/i386-linux-gnu/libsqlite3.so.0
/usr/lib/i386-linux-gnu/libsqlite3.so.0.8.6
/usr/lib/x86_64-linux-gnu/libsqlite3.a
/usr/lib/x86_64-linux-gnu/libsqlite3.la
/usr/lib/x86_64-linux-gnu/libsqlite3.so
/usr/lib/x86_64-linux-gnu/libsqlite3.so.0
/usr/lib/x86_64-linux-gnu/libsqlite3.so.0.8.6
/usr/local/lib/libsqlite3.a
/usr/local/lib/libsqlite3.la
/usr/local/lib/libsqlite3.so
/usr/local/lib/libsqlite3.so.0
/usr/local/lib/libsqlite3.so.0.8.6
Controllando le date (controllate effettivamente, non vorrei che proprio nel vostro caso i problemi fossero altri) si vedrà che i file delle directory usr/lib/i386-linux-gnu/ e /usr/lib/x86_64-linux-gnu/ non sono aggiornati alla stessa data di quelli nella directory /usr/local/lib/, i più recenti appena installati.
Su Ubuntu 64 bit è sufficiente aggiornare i file nella sola directory /usr/lib/x86_64-linux-gnu/ copiandovi quelli della directory /usr/local/lib/.
Immagino, ma NON ho testato l'ipotesi, che per installazioni di Ubuntu a 32 bit la directory /usr/lib/x86_64-linux-gnu/ va sostituita con la directory /usr/lib/i386-linux-gnu/.
Perché SQLite riprenda a funzionare è sufficiente aggiornare solo i 2 file libsqlite3.so.0 e libsqlite3.so.0.8.6, per mantenere il tutto allineato è preferibile aggiornarli tutti.
Per sicurezza è meglio cambiare nome ai file da aggiornare piuttosto che cancellarli o sovrascriverli, così da poter tornare indietro in caso di necessità:
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.a /usr/lib/x86_64-linux-gnu/libsqlite3.a_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.la /usr/lib/x86_64-linux-gnu/libsqlite3.la_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.so /usr/lib/x86_64-linux-gnu/libsqlite3.so_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.so.0 /usr/lib/x86_64-linux-gnu/libsqlite3.so.0_bak
sudo mv /usr/lib/x86_64-linux-gnu/libsqlite3.so.0.8.6 /usr/lib/x86_64-linux-gnu/libsqlite3.so.0.8.6_bak
Infine copiare i nuovi file al posto dei vecchi rinominati:
sudo cp /usr/local/lib/libsqlite3.a /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.la /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.so /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.so.0 /usr/lib/x86_64-linux-gnu/
sudo cp /usr/local/lib/libsqlite3.so.0.8.6 /usr/lib/x86_64-linux-gnu/
Se tutto è stato fatto correttamente ora SQLite dovrebbe funzionare. Provate a ridare il comando:
sqlite3
e SQLite dovrebbe rispondervi:
SQLite version 3.8.1 2013-10-17 12:57:35
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
>
Per uscire dal prompt e terminare SQLite:
.q
Per disinstallarlo completamente:
sudo apt-get remove --purge sqlite-autoconf
E' tutto... buon lavoro con SQLite!
sabato 17 novembre 2007
Linux: comandi info, apropos, whatis per ulteriori informazione sui comandi
Sempre per non perderci nella foresta dei comandi Linux, dopo il post scorso sull'uso di man, l'interfaccia da shell alla documentazione presente sul vostro sistema Linux, in questo post conclusivo sull'argomento vi mostro altri 3 comandi per accedere ad ulteriore documentazione:
Potrete saltare da una pagina all'altra premendo invio quando il cursore è su un termine che contiene un rimando ad un'altra pagina. Premendo u si torna al livello precedente, con n si passa alla pagina seguente, con p alla precedente, i torna all'indice, / permette di fare ricerche, ? mostra i comandi disponibili.
Passiamo ora al comando
Scopriamo così che ls si trova nella sezione 1 dei manuali e dalla descrizione del comando capiamo cosa fa, la stessa descrizione, ripeto, che il comando man ls presenta nella prima sezione NAME. In realtà
Tenetelo presente: quando chiedete a
Ultimo comando di cui ci occupiamo è
Bene, e con questo abbiamo terminato il veloce sguardo agli strumenti grazie alla quale avere rapidamente informazioni sui comandi Linux. Naturalmente rimane il web come ulteriore fonte d'informazione, ma lì non credo di dovervi dire qualcosa: voglio solo segnalarvi due ottime fonti di informazioni che trovate nella barra di navigazione sinistra, alla sezione "Risorse sul Web": si tratta di "Appunti di informatica libera" e di "Truelite"; entrambi in italiano, chiare, complete, e molto molto utili per approfondire quanto andremo a vedere nei prossimi post sull'argomento. A presto. :)
@:\>
info, whatis e apropos.Info in qualche modo è analogo a man: per usarlo basterà dare il comando info nomecomando e anch'esso permette di accedere alla documentazione dei comandi, ma le due documentazioni non sono equivalenti: alcune cose infatti che trovate nei file di man non le trovate in quelli di info e viceversa. Anche il sistema di consultazione è diverso: quello di info è un pò più ostico trattandosi di pagine ipertestuali.Potrete saltare da una pagina all'altra premendo invio quando il cursore è su un termine che contiene un rimando ad un'altra pagina. Premendo u si torna al livello precedente, con n si passa alla pagina seguente, con p alla precedente, i torna all'indice, / permette di fare ricerche, ? mostra i comandi disponibili.
Passiamo ora al comando
whatis. Nel post precedente vi avevo spiegato come i manuali sono raccolti in sezioni: whatis nomecomando restituisce il numero della sezione del manuale in cui ha trovato la stringa "nomecomando" ed una sua descrizione, quella che potete vedere nella sezione NAME quando ad esempio avete dato il comando man ls, proprio all'inizio della schermata. Esempio:$ whatis ls
ls (1) - list directory contentsScopriamo così che ls si trova nella sezione 1 dei manuali e dalla descrizione del comando capiamo cosa fa, la stessa descrizione, ripeto, che il comando man ls presenta nella prima sezione NAME. In realtà
whatis così non è poi di grandissima utilità, a meno di trovarci in questa situazione:$ whatis passwd
passwd (1) - change user password
passwd (1ssl) - compute password hashes
passwd (5) - the password fileWhatis ci restituisce tutte le occorrenze di passwd con tanto di indicazione della sezione in cui si trova e ovviamente la breve descrizione del comando. Per come è congegnato man, quando diamo il comando man passwd ci viene mostrata solo la prima occorrenza, per visualizzare le altre 2 occorre indicarle esplicitamente, per esempio:man 5 passwdTenetelo presente: quando chiedete a
man un certo comando ma vi compare altro, controllate con whatis la presenza di altre voci che siano maggiormente corrispondenti a quanto cercate.Ultimo comando di cui ci occupiamo è
apropos "nome comando": cerca la stringa corrispondente a "nome comando" nella sezione DESCRIPTION delle pagine visualizzate da man, notare l'uso degli apici per parole composte.Bene, e con questo abbiamo terminato il veloce sguardo agli strumenti grazie alla quale avere rapidamente informazioni sui comandi Linux. Naturalmente rimane il web come ulteriore fonte d'informazione, ma lì non credo di dovervi dire qualcosa: voglio solo segnalarvi due ottime fonti di informazioni che trovate nella barra di navigazione sinistra, alla sezione "Risorse sul Web": si tratta di "Appunti di informatica libera" e di "Truelite"; entrambi in italiano, chiare, complete, e molto molto utili per approfondire quanto andremo a vedere nei prossimi post sull'argomento. A presto. :)
@:\>
giovedì 15 novembre 2007
Linux: man, informazioni sui comandi
Abbiamo già visto nel post precedente, come la shell non sia altro che un'interfaccia di tipo testo con cui dare comandi a Linux. Non clicchiamo su qualcosa, niente tasto destro o sinistro: solo testo, puro testo, nient'altro che testo. Ed una vera foresta di comandi mnemonici da mandar giù, con ancora più opzioni da poter usare per ognuno di essi, in cui soprattutto chi proviene da Windows o più in generale gli amanti dell'interfaccia grafica potrebbe/protrebbero facilmente perdersi.
Prima di andare perciò dispersi in questa selva oscura, voglio condividere con voi altre informazioni di base per non perderci mai, o quanto meno ritrovarci nel caso "che la diritta via era smarrita". Linux infatti è molto ben documentato, e per ogni comando c'è la possibilità di averne immediatamente una descrizione e la lista della sue possibili opzione tramite un apposito comando: man.
Man è un'interfaccia ai manuali disponibili sul vostro sistema consultabili da shell. Prende in input i file contenenti questi manuali scritti in un linguaggio di formattazione chiamato Troff (come concetto analogo all'HTML nel senso che all'interno dello testo stesso vi sono anche le istruzioni di formattazione), e produce qualcosa di simile a quanto riportato più sotto.
Facciamo un esempio concreto: tramite il comando
(il $ rappresenta il prompt, anch'esso spiegato nel post precedente), otterrete quanto segue:
Come potete vedere man formatta a video una serie di informazioni sul comando ls:
- per comodità infatti il manuale è stato diviso in sezione, una per ogni tipologia di comandi, ls è nella prima (1), la sezione dei comandi utente (user commands);
- NAME contiene il nome del comando così come va scritto nella shell ed una sua breve descrizione;
- SINOPSYS indica come va usato il comando in tutti i possibili casi, comprese le eventuali opzioni e gli argomenti;
- DESCRIPTION fornisce una descrizione più dettagliata del comando;
- segue la lista dei possibili argomenti del comando con la loro descrizione.
Per muovervi all'interno di documenti molto lunghi premete i tasti "page up" e "page down" ("Pag con freccia all'insù" e "Pag con freccia all'ingiù" sulla vostra tastiera) e potrete andare su e giù nel testo visualizzandone la parte che v'interessa.
Cercate un termine all'interno del testo? Premete il tasto "/" (sopra il 7 nella tastiera italiana) e scrivete la stringa cercata, poi date invio. Man vi evidenzierà tutto le occorrenze trovate.
Ma non finisce qua: man fa altre mille cosette simpatiche. Quali? Beh, chi meglio di man stesso può dirvelo. Date il comando
Si esatto, come avrete già immaginato, abbiamo chiesto a man di visualizzare il suo stesso manuale. Consultatelo usando una Ubuntu, trovete in italiano tutta una serie di utili descrizioni sul modo in cui sono organizzati i manuali, e capirete meglio l'output di man quando avete chiesto informazioni sul comando ls.
Ultima cosa: quando avete terminato la consultazione e volete uscire dalla pagina di manuale, premete il tasto "q", sta per quit.
@:\>
Prima di andare perciò dispersi in questa selva oscura, voglio condividere con voi altre informazioni di base per non perderci mai, o quanto meno ritrovarci nel caso "che la diritta via era smarrita". Linux infatti è molto ben documentato, e per ogni comando c'è la possibilità di averne immediatamente una descrizione e la lista della sue possibili opzione tramite un apposito comando: man.
Man è un'interfaccia ai manuali disponibili sul vostro sistema consultabili da shell. Prende in input i file contenenti questi manuali scritti in un linguaggio di formattazione chiamato Troff (come concetto analogo all'HTML nel senso che all'interno dello testo stesso vi sono anche le istruzioni di formattazione), e produce qualcosa di simile a quanto riportato più sotto.
Facciamo un esempio concreto: tramite il comando
man ls visualizziamo le pagine del manuale del comando ls usato per avere la lista dei file contenuti in una directory. Aprite la shell (come fare lo trovate nel post precedente), e date il comando$ man ls(il $ rappresenta il prompt, anch'esso spiegato nel post precedente), otterrete quanto segue:
LS(1) User Commands LS(1)
NAME
ls - list directory contents
SYNOPSIS
ls [OPTION]... [FILE]...
DESCRIPTION
List information about the FILEs (the current directory by default). Sort entries alphabetically if none of -cftuvSUX nor --sort.
Mandatory arguments to long options are mandatory for short options too.
-a, --all
do not ignore entries starting with .
-A, --almost-all
do not list implied . and ..
--author
with -l, print the author of each file
-b, --escape
print octal escapes for nongraphic characters
--block-size=SIZE
use SIZE-byte blocks
-B, --ignore-backups
do not list implied entries ending with ~
-c with -lt: sort by, and show, ctime (time of last modification of file status information) with -l: show ctime and sort by name otherwise: sort
by ctime
-C list entries by columns
--color[=WHEN]
control whether color is used to distinguish file types. WHEN may be ‘never’, ‘always’, or ‘auto’
-d, --directory
list directory entries instead of contents, and do not dereference symbolic links
Manual page ls(1) line 1/208 18%Come potete vedere man formatta a video una serie di informazioni sul comando ls:
- per comodità infatti il manuale è stato diviso in sezione, una per ogni tipologia di comandi, ls è nella prima (1), la sezione dei comandi utente (user commands);
- NAME contiene il nome del comando così come va scritto nella shell ed una sua breve descrizione;
- SINOPSYS indica come va usato il comando in tutti i possibili casi, comprese le eventuali opzioni e gli argomenti;
- DESCRIPTION fornisce una descrizione più dettagliata del comando;
- segue la lista dei possibili argomenti del comando con la loro descrizione.
Per muovervi all'interno di documenti molto lunghi premete i tasti "page up" e "page down" ("Pag con freccia all'insù" e "Pag con freccia all'ingiù" sulla vostra tastiera) e potrete andare su e giù nel testo visualizzandone la parte che v'interessa.
Cercate un termine all'interno del testo? Premete il tasto "/" (sopra il 7 nella tastiera italiana) e scrivete la stringa cercata, poi date invio. Man vi evidenzierà tutto le occorrenze trovate.
Ma non finisce qua: man fa altre mille cosette simpatiche. Quali? Beh, chi meglio di man stesso può dirvelo. Date il comando
$ man manSi esatto, come avrete già immaginato, abbiamo chiesto a man di visualizzare il suo stesso manuale. Consultatelo usando una Ubuntu, trovete in italiano tutta una serie di utili descrizioni sul modo in cui sono organizzati i manuali, e capirete meglio l'output di man quando avete chiesto informazioni sul comando ls.
Ultima cosa: quando avete terminato la consultazione e volete uscire dalla pagina di manuale, premete il tasto "q", sta per quit.
@:\>
mercoledì 14 novembre 2007
Linux: la shell, la vostra centrale di comando
Con il post "Linux: avvio e funzionamento del kernel" abbiamo concluso una prima serie di post intesi a comprendere le basi dell'architettura di un sistema Linux. I prossimi sono post di passaggio prima di addentrarci nella giungla dei comandi Linux: una vera foresta in cui sopratutto chi proviene da Windows o più in generale gli amanti dell'interfaccia grafica, potrebbero facilmente perdersi. E in questo non siamo per niente aiutati dal front-end, dall'interfaccia usata per dare i comandi: la shell.
La shell non è altro che un'interfaccia di tipo testo fra noi e Linux. Come tutto il resto anch'essa è un programma, ed infatti esiste più di una shell. Alcune sono caratterizzate da grande leggerezza e un fabbisogno limitato di risorse, altre da comandi molto potenti, altre ancora dall'aderenza agli standard Posix. Quella di default sulla maggioranza delle distribuzione, tra cui anche le nostre due di riferimento, Mandriva e Ubuntu, è la bash (Bourne Again SHell).
Il nome ed il modo di avviare la bash cambia a seconda che stiate usando l'interfaccia grafica Gnome (quella di Ubuntu per esempio) o KDE (di default in Mandriva): nella prima si chiama Terminale e potete avviarla come in fig. 1,

fig. 1
nella seconda si chiama Konsole (è consuetudine aggiugere una k iniziale nelle applicazioni KDE) e la potete avviare come in fig. 2.

fig. 2
Una volta avviata, la shell mostrerà un prompt, un testo all'inizio di ogni riga, che contiene una serie di informazioni utili; vediamo quelle della bash in Ubuntu (fig. 3):
- la parte prima della "@" è il vostro nome utente (o userid);
- la parte successiva alla "@" che termina dove ci sono i ":" è il nome con cui viene vista la vostra macchina all'interno di una rete;
- il simbolo "~" (tilde) per convenzione in Linux indica la vostra directory home. Dato che la home di un utente ha come nome quello dell'utente stesso, in fig. 3 allora ci troviamo nella directory
- il simbolo "$" (dollaro) finale sta ad indicare che in questo momento siete un utente normale, se fosse il simbolo "#" invece siete l'amministratore; ricordatelo quando siete in dubbio se siete in modalità amministrativa o utente normale, nel primo caso dovete essere molto più attenti per la portata maggiore dei danni che potreste fare.

fig. 3
Due sono le funzionalità della bash che voglio mostrarvi, sono semplici ma di grande utilità; riguardano entrambi lo storico dei comandi precedentemente dati:
1) premendo il tasto "freccia su" della vostra tastiera potrete navigare all'indietro ed uno alla volta, tutto lo storico dei comandi già dati nella shell. Fate una prova, date i comandi:
Vi ricordo che il simbolo dollaro "$" del prompt sta ad indicare che siete in modalità utente normale. Ora premete "freccia su" e uno alla volta lì vedrete ricomparire tutti in ordine inverso, dal comando più recente a quello più datato.
2) dando il comando
Ecco, con solo questi due piccoli aiuti da parte della shell, il vostro lavoro diventerà molto più veloce e leggero, niente più riscrittura degli stessi noiosi comandi, soprattutto quando sono composti dal concatenamento di tanti singoli comandi che prossimamente vedremo.
@:\>
La shell non è altro che un'interfaccia di tipo testo fra noi e Linux. Come tutto il resto anch'essa è un programma, ed infatti esiste più di una shell. Alcune sono caratterizzate da grande leggerezza e un fabbisogno limitato di risorse, altre da comandi molto potenti, altre ancora dall'aderenza agli standard Posix. Quella di default sulla maggioranza delle distribuzione, tra cui anche le nostre due di riferimento, Mandriva e Ubuntu, è la bash (Bourne Again SHell).
Il nome ed il modo di avviare la bash cambia a seconda che stiate usando l'interfaccia grafica Gnome (quella di Ubuntu per esempio) o KDE (di default in Mandriva): nella prima si chiama Terminale e potete avviarla come in fig. 1,
fig. 1
nella seconda si chiama Konsole (è consuetudine aggiugere una k iniziale nelle applicazioni KDE) e la potete avviare come in fig. 2.
fig. 2
Una volta avviata, la shell mostrerà un prompt, un testo all'inizio di ogni riga, che contiene una serie di informazioni utili; vediamo quelle della bash in Ubuntu (fig. 3):
- la parte prima della "@" è il vostro nome utente (o userid);
- la parte successiva alla "@" che termina dove ci sono i ":" è il nome con cui viene vista la vostra macchina all'interno di una rete;
- il simbolo "~" (tilde) per convenzione in Linux indica la vostra directory home. Dato che la home di un utente ha come nome quello dell'utente stesso, in fig. 3 allora ci troviamo nella directory
/home/occhipervinca;- il simbolo "$" (dollaro) finale sta ad indicare che in questo momento siete un utente normale, se fosse il simbolo "#" invece siete l'amministratore; ricordatelo quando siete in dubbio se siete in modalità amministrativa o utente normale, nel primo caso dovete essere molto più attenti per la portata maggiore dei danni che potreste fare.
fig. 3
Due sono le funzionalità della bash che voglio mostrarvi, sono semplici ma di grande utilità; riguardano entrambi lo storico dei comandi precedentemente dati:
1) premendo il tasto "freccia su" della vostra tastiera potrete navigare all'indietro ed uno alla volta, tutto lo storico dei comandi già dati nella shell. Fate una prova, date i comandi:
$ ls che vi presenta la lista dei file della directory in cui vi trovate,$ cd / per portarvi nella radice del vostro filesystem (è pressappoco come essere in C: in Windows),$ ls -l, che mostra molte più informazioni del solo ls.Vi ricordo che il simbolo dollaro "$" del prompt sta ad indicare che siete in modalità utente normale. Ora premete "freccia su" e uno alla volta lì vedrete ricomparire tutti in ordine inverso, dal comando più recente a quello più datato.
2) dando il comando
hystory vedrete riportata tutta la lista dei comandi dati preceduti da un numero. Se volete eseguire un certo comando presente nella lista, è sufficiente dare !numero per vederlo eseguito.Ecco, con solo questi due piccoli aiuti da parte della shell, il vostro lavoro diventerà molto più veloce e leggero, niente più riscrittura degli stessi noiosi comandi, soprattutto quando sono composti dal concatenamento di tanti singoli comandi che prossimamente vedremo.
@:\>
martedì 13 novembre 2007
Linux: avvio e funzionamento del kernel
All'accensione del PC, il primo programma ad essere eseguito è contenuto direttamente nel firmware della macchina: il BIOS (Basic Input/Output System). Questo programma effettua tutta una serie di controlli sull'hardware che se conclusi correttamente portano alla fase successiva: l'avvio, dal dispositivo indicato nelle impostazioni del bios, del bootloader. L'unico compito del bootloader è cercare un'immagine del kernel, caricarla in memoria e avviarla.
Partito il kernel, questi prende il controllo della macchina, effettua una serie di operazione di inizializzazione come la scansione delle periferiche disponibili, e infine lancia il primo processo di un sistema Linux, init. In realtà questa è solo una convenzione sul nome del primo processo da lanciare; in sistemi embedded ad esempio, cioè quei sistemi adibiti ad un singolo compito quali un comune telefonino, in genere viene lanciato altro.
Init, sfruttando la possibilità di un processo di lanciare a sua volta un altro processo (il primo è detto padre, il secondo figlio, Init è quindi il padre di tutti i processi Linux), lancia altri programmi che a loro volta lanciano ancora altri programmi, tutto questo fino a che sono partiti tutti i programmi che servono per il corretto funzionamento dell'intero sistema operativo.
Ma come funziona l'intero sistema operativo basandosi su un kernel che può fare solo le poche cose già viste nel post "Linux: architettura di base"? Guardate fig. 1 mentre vi spiego.

fig. 1
Abbiamo già accennato al fatto che il kernel è l'unico che può accedere direttamente all'hardware della macchina: grazie alle sue tre sezioni, scheduler, virtual memory, driver sfrutta la potenza e le risorse della macchina e le rende disponibili ai processi.
Quando un programma (e quindi uno dei processi da cui è costituito) ha bisogno per esempio di altra memoria, la chiede ad un apposito programma contenuto nel sottostante livello chiamato GNU C Library (guardate fig. 1), una serie di programmi scritti in linguaggio C. Questo a sua volta, invoca un'apposita funzione del sottostante livello chiamato System Call Interface (Interfaccia alle Chiamate di Sistema). Queste sono funzioni rese disponibili dal kernel per poterlo informare che si ha bisogno di qualcosa da lui. Ora il kernel sa che un processo ha bisogno di più memoria, e tramite l'apposita sezione del Virtual Memory provvede a fornirgliela.
Si può notare una netta separazione fra lo spazio in cui si trovano a girare i programmi, detto User Space (Spazio Utente), da cui non vi accesso diretto all'hardware, e lo spazio in cui gira il kernel, detto Kernel Space, da cui invece si accede direttamente all'hardware; ecco perché solo il kernel può accedere direttamente all'hardare, mentre i processi girando in user space ne sono impossibilitati.
Il compito del kernel è unicamente quello di rendere disponibili le risorse hardware ai processi facendo da interfaccia fra questi due, di suo non effettua nessun'altra operazione. E' questo il motivo per cui in Linux tutto è realizzato tramite un programma: dalla semplice copia di un file all'intero filesystem passando per l'interfaccia grafica, si tratta sempre di programmi eseguiti in User Space, il kernel in se non ha disponibile nessuna di queste funzionalità.
Lungi dell'essere un limite, questo è invece un grande vantaggio di Linux: è per questo motivo che ad esempio, potete usare più interfacce grafiche (due su tutte, Gnome e KDE) invece dell'unica che ad esempio si può utilizzare in Windows. Ed è sempre per questo motivo che, se in Windows potete usare il solo filesystem NTFS (oppure il FAT, ormai obsoleto ma ancora utile in certe situazione), in Linux ne potete usare una buona decina tra cui anche NTFS.
Chi ha avuto modo di installare Ubuntu 7.10 direttamente sul PC, senza usare VirtualBox o altri virtualizzatori, si sarà accorto come la partizione di Windows gli compare direttamente sul desktop come fosse un normale disco rigido di Linux: potete navigarlo a vostro piacimento e fare qualunque operazione vogliate sui file che contiene nonostante si tratti di un filesystem Windows. Ecco, questa è la potenza dell'approccio "tutto è un programma" di Linux.
@:\>
Partito il kernel, questi prende il controllo della macchina, effettua una serie di operazione di inizializzazione come la scansione delle periferiche disponibili, e infine lancia il primo processo di un sistema Linux, init. In realtà questa è solo una convenzione sul nome del primo processo da lanciare; in sistemi embedded ad esempio, cioè quei sistemi adibiti ad un singolo compito quali un comune telefonino, in genere viene lanciato altro.
Init, sfruttando la possibilità di un processo di lanciare a sua volta un altro processo (il primo è detto padre, il secondo figlio, Init è quindi il padre di tutti i processi Linux), lancia altri programmi che a loro volta lanciano ancora altri programmi, tutto questo fino a che sono partiti tutti i programmi che servono per il corretto funzionamento dell'intero sistema operativo.
Ma come funziona l'intero sistema operativo basandosi su un kernel che può fare solo le poche cose già viste nel post "Linux: architettura di base"? Guardate fig. 1 mentre vi spiego.
fig. 1
Abbiamo già accennato al fatto che il kernel è l'unico che può accedere direttamente all'hardware della macchina: grazie alle sue tre sezioni, scheduler, virtual memory, driver sfrutta la potenza e le risorse della macchina e le rende disponibili ai processi.
Quando un programma (e quindi uno dei processi da cui è costituito) ha bisogno per esempio di altra memoria, la chiede ad un apposito programma contenuto nel sottostante livello chiamato GNU C Library (guardate fig. 1), una serie di programmi scritti in linguaggio C. Questo a sua volta, invoca un'apposita funzione del sottostante livello chiamato System Call Interface (Interfaccia alle Chiamate di Sistema). Queste sono funzioni rese disponibili dal kernel per poterlo informare che si ha bisogno di qualcosa da lui. Ora il kernel sa che un processo ha bisogno di più memoria, e tramite l'apposita sezione del Virtual Memory provvede a fornirgliela.
Si può notare una netta separazione fra lo spazio in cui si trovano a girare i programmi, detto User Space (Spazio Utente), da cui non vi accesso diretto all'hardware, e lo spazio in cui gira il kernel, detto Kernel Space, da cui invece si accede direttamente all'hardware; ecco perché solo il kernel può accedere direttamente all'hardare, mentre i processi girando in user space ne sono impossibilitati.
Il compito del kernel è unicamente quello di rendere disponibili le risorse hardware ai processi facendo da interfaccia fra questi due, di suo non effettua nessun'altra operazione. E' questo il motivo per cui in Linux tutto è realizzato tramite un programma: dalla semplice copia di un file all'intero filesystem passando per l'interfaccia grafica, si tratta sempre di programmi eseguiti in User Space, il kernel in se non ha disponibile nessuna di queste funzionalità.
Lungi dell'essere un limite, questo è invece un grande vantaggio di Linux: è per questo motivo che ad esempio, potete usare più interfacce grafiche (due su tutte, Gnome e KDE) invece dell'unica che ad esempio si può utilizzare in Windows. Ed è sempre per questo motivo che, se in Windows potete usare il solo filesystem NTFS (oppure il FAT, ormai obsoleto ma ancora utile in certe situazione), in Linux ne potete usare una buona decina tra cui anche NTFS.
Chi ha avuto modo di installare Ubuntu 7.10 direttamente sul PC, senza usare VirtualBox o altri virtualizzatori, si sarà accorto come la partizione di Windows gli compare direttamente sul desktop come fosse un normale disco rigido di Linux: potete navigarlo a vostro piacimento e fare qualunque operazione vogliate sui file che contiene nonostante si tratti di un filesystem Windows. Ecco, questa è la potenza dell'approccio "tutto è un programma" di Linux.
@:\>
lunedì 12 novembre 2007
Linux: architettura di base
Che lo abbiate installato su una macchina virtuale di VirtualBox oppure direttamente sul vostro PC, da un liveCD oppure da Windows usando Wubi, è arrivato il momento di guardare da vicino come funziona un sistema operativo Linux.
Linux è un sistema operativo multitasking e multiutente, ossia può gestire più processi e più utenti contemporaneamente (un processo è l'unita minima di elaborazione di un programma).
Il cuore di un sistema operativo è il kernel. Quello di Linux si occupa solamente di una cosa: eseguire processi sfruttando le risorse hardware della macchina su cui gira. Tutto il resto, dai servizi di sistema all'interfaccia grafica, è ottenuto facendo girare un programma. Il kernel di per se non offre nessuno di questi servizi: non offre ad esempio funzionalità per copiare i file, non offre un'interfaccia utente, ne di testo ne di tipo grafico.
Quando usate un'interfaccia grafica come Gnome o KDE, queste non sono funzionalità offerte dal kernel, bensì normalissimi programmi esterni al kernel, al pari di un OpenOffice.org o Firefox. Ecco perché in Linux potete scegliere più interfacce grafiche, è semplicemente un programma come tutti gli altri. In Windows invece l'interfaccia grafica è integrata nel sistema operativo, ed in alcune versioni, anche il browser per la navigazione Internet.
Quando diciamo Linux poi, non stiamo riferendoci all'intero sistema operativo, ma solo al kernel. Sfruttando i servizi che questi mette a disposizione, una moltitudine di programmi si occupa di fornire tutte le funzionalità che ci si aspetta da un moderno sistema operativo. Questi programmi arrivano direttamente, o derivano in qualche modo, dal progetto GNU della Free Software Foundation: ecco perché in generale si parla di sistema operativo GNU/Linux.
Infine, quella che comunemente viene chiamata distribuzione, Debian, Ubuntu, openSUSE, RedHat solo per fare qualche nome fra le più conosciute, è l'insieme del sistema operativo GNU/Linux più una raccolta coerente di programmi usati dagli utenti per le loro normali attività: programmi di grafica, produttività personale, navigazione Internet, player audio/video e così via.
Da qui in poi però, per semplificarci la vita, un sistema operativo GNU/Linux continueremo a chiamarlo con il solo termine Linux.
Ok, accordatici sulla terminologia da usare, torniamo ora ad occuparci del kernel vedendo quali sono le poche ma fondamentali mansioni che svolge per darci l'unico servizio che offre: eseguire processi, l'unità minima di elaborazione di un programma. Queste mansioni sono svolte dalle tre sottosezioni del KERNEL visibili in fig. 1:
fig. 1
- gestione dei processi tramite lo Scheduler.
Questa parte del kernel si occupa di tutto ciò che riguarda la gestione di un processo, ad esempio di stabilire l'ordine di esecuzione dei processi, l'esecuzione stessa, la sospensione dell'elaborazione, la ripresa, lo stop e così via.
- gestione della memoria tramite il Virtual Memory (VM).
La memoria fisica non è liberamente accessibile ai processi. E' il VM che, anche con l'aiuto del Memory Management Unit (MMU), apposita unità presente direttamente nell'hardware dei microprocessori, rimappa opportunamente quella fisica in uno spazio virtuale che rende disponibile al processo. In questo modo, ogni processo non accede mai alla memoria reale del sistema, ma solo a quella resagli disponibile dal VM.
Sigillato all'interno del suo spazio di memoria, il processo non può creare problemi accedendo per sbaglio allo spazio di un altro processo (chi ha usato le prime versioni di Windows, sa quanto fossero frequenti i blocchi dell'intero sistema causati proprio da problemi di questo tipo). Quando la memoria RAM poi per qualche motivo diventa insufficiente, è sempre il VM a gestire lo swap, lo spostamento cioè di parti della memoria sul disco fisso per liberare spazio.
- gestione delle periferiche tramite i Driver.
Questa indicazione generica è relativa a quella parte del kernel che si occupa di accedere alle periferiche rendendole disponibili ai programmi. La particolarità di questa sezione è che fornisce un modalità comune (un'interfaccia) di accesso a periferiche anche molto diverse fra loro, porte seriali, dischi rigidi, scheda audio tanto per fare degli esempi, trattandole tutte come se fossero dei file; da qui uno dei motti di Linux: tutto è un file. Vedremo successivamente come ciò sia possibile e i vantaggi di questo approccio.
Ecco, questa è in estrema sintesi l'architettura di un sistema Linux, giusto per iniziare a capire; in realtà le cose sono ben più complesse, provate a dare un'occhiata a questa mappa interattiva del kernel di Linux e vi renderete conto.
@:\>
Linux è un sistema operativo multitasking e multiutente, ossia può gestire più processi e più utenti contemporaneamente (un processo è l'unita minima di elaborazione di un programma).
Il cuore di un sistema operativo è il kernel. Quello di Linux si occupa solamente di una cosa: eseguire processi sfruttando le risorse hardware della macchina su cui gira. Tutto il resto, dai servizi di sistema all'interfaccia grafica, è ottenuto facendo girare un programma. Il kernel di per se non offre nessuno di questi servizi: non offre ad esempio funzionalità per copiare i file, non offre un'interfaccia utente, ne di testo ne di tipo grafico.
Quando usate un'interfaccia grafica come Gnome o KDE, queste non sono funzionalità offerte dal kernel, bensì normalissimi programmi esterni al kernel, al pari di un OpenOffice.org o Firefox. Ecco perché in Linux potete scegliere più interfacce grafiche, è semplicemente un programma come tutti gli altri. In Windows invece l'interfaccia grafica è integrata nel sistema operativo, ed in alcune versioni, anche il browser per la navigazione Internet.
Quando diciamo Linux poi, non stiamo riferendoci all'intero sistema operativo, ma solo al kernel. Sfruttando i servizi che questi mette a disposizione, una moltitudine di programmi si occupa di fornire tutte le funzionalità che ci si aspetta da un moderno sistema operativo. Questi programmi arrivano direttamente, o derivano in qualche modo, dal progetto GNU della Free Software Foundation: ecco perché in generale si parla di sistema operativo GNU/Linux.
Infine, quella che comunemente viene chiamata distribuzione, Debian, Ubuntu, openSUSE, RedHat solo per fare qualche nome fra le più conosciute, è l'insieme del sistema operativo GNU/Linux più una raccolta coerente di programmi usati dagli utenti per le loro normali attività: programmi di grafica, produttività personale, navigazione Internet, player audio/video e così via.
Da qui in poi però, per semplificarci la vita, un sistema operativo GNU/Linux continueremo a chiamarlo con il solo termine Linux.
Ok, accordatici sulla terminologia da usare, torniamo ora ad occuparci del kernel vedendo quali sono le poche ma fondamentali mansioni che svolge per darci l'unico servizio che offre: eseguire processi, l'unità minima di elaborazione di un programma. Queste mansioni sono svolte dalle tre sottosezioni del KERNEL visibili in fig. 1:
fig. 1
- gestione dei processi tramite lo Scheduler.
Questa parte del kernel si occupa di tutto ciò che riguarda la gestione di un processo, ad esempio di stabilire l'ordine di esecuzione dei processi, l'esecuzione stessa, la sospensione dell'elaborazione, la ripresa, lo stop e così via.
- gestione della memoria tramite il Virtual Memory (VM).
La memoria fisica non è liberamente accessibile ai processi. E' il VM che, anche con l'aiuto del Memory Management Unit (MMU), apposita unità presente direttamente nell'hardware dei microprocessori, rimappa opportunamente quella fisica in uno spazio virtuale che rende disponibile al processo. In questo modo, ogni processo non accede mai alla memoria reale del sistema, ma solo a quella resagli disponibile dal VM.
Sigillato all'interno del suo spazio di memoria, il processo non può creare problemi accedendo per sbaglio allo spazio di un altro processo (chi ha usato le prime versioni di Windows, sa quanto fossero frequenti i blocchi dell'intero sistema causati proprio da problemi di questo tipo). Quando la memoria RAM poi per qualche motivo diventa insufficiente, è sempre il VM a gestire lo swap, lo spostamento cioè di parti della memoria sul disco fisso per liberare spazio.
- gestione delle periferiche tramite i Driver.
Questa indicazione generica è relativa a quella parte del kernel che si occupa di accedere alle periferiche rendendole disponibili ai programmi. La particolarità di questa sezione è che fornisce un modalità comune (un'interfaccia) di accesso a periferiche anche molto diverse fra loro, porte seriali, dischi rigidi, scheda audio tanto per fare degli esempi, trattandole tutte come se fossero dei file; da qui uno dei motti di Linux: tutto è un file. Vedremo successivamente come ciò sia possibile e i vantaggi di questo approccio.
Ecco, questa è in estrema sintesi l'architettura di un sistema Linux, giusto per iniziare a capire; in realtà le cose sono ben più complesse, provate a dare un'occhiata a questa mappa interattiva del kernel di Linux e vi renderete conto.
@:\>
Iscriviti a:
Post (Atom)